(1)では、Chatworkのリクエスト数やログの量など、Chatworkのログの背景をお伝えしました。
このブログでは、それらに対応している構成や、その構成になる前の話を記載したいと思います。
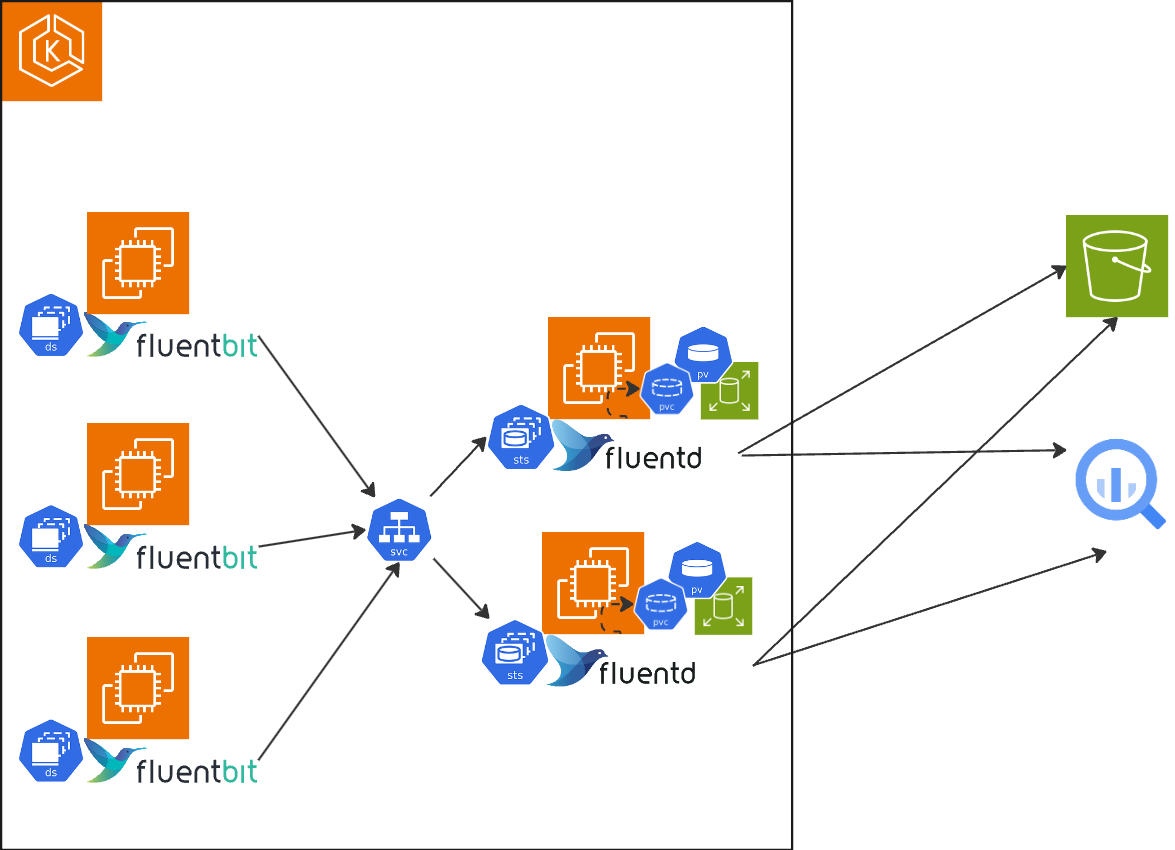
再掲ですが、Chatworkでは下記のように各ノードのforwarderとしてfluent-bit、aggregatorとしてfluentdというfluent兄弟を両方使っています。
現構成の前
一番ありがちな、各ノードにDaemonsetとしてfluentdを配置し、そのfluentdから直接S3などにログを送っていました。

この構成のときには、kube-fluentd-operatorというのを利用していました。
namespaceやlabelでconfigを書くことができ、それをよしなに実際のfluentdのconfigに書き直し、変更があればreloadしてくれるアプリケーションです。
これはこれで便利ではあったのですが、そもそものfluentdがリソースをたくさん使う、ということもあり、fluentdのメモリは本番環境では768Miに設定していました。
さらにある程度起動し続けると、OOMループが始まるため、週2でPodをすべて入れ替えるためのcronjobを動かしていて、パフォーマンスに問題がある状態でした。
しかもこの構成のときには、(1)で記載したモノリスアプリケーションのKubernetesへの移行前で、下記のブログに記載されているモノリスアプリケーションから切り出したいくつかのマイクロサービスが動いているだけの状態でした。
とはいえ、メッセージングまわりのアプリケーションなので、それなりにログは多いです。
モノリスアプリケーションを移行するときにログ周りが問題になるのは明らかでした。
fluent-bitの導入とforwarder, aggregatorの構成になるまで
以上のような背景から、まずはノードのログを収集する部分にfluent-bitを導入しよう、ということになりました。
これは単純にパフォーマンスの観点からの判断です。
すこし前の資料ではありますが、当時判断した際に参考にさせていただいた資料です。
この5倍以上のスループットを実現するパフォーマンスが、(もちろん設定次第にはなりますが)少メモリで実現できることが判断の決め手になりました。
公式の資料では具体的なスループットは乗っていませんが、少メモリであることがわかります。
fluent-bitへの変更
最初にfluent-bitを導入した際は、上記のfluentdをfluent-bitに変えただけで、直接S3などに送っていました。
当時はfluent-bit本体にS3 Pluginがなく、下記を利用してS3に送信していました。
しかし、ここで問題が。fluent-bit-goのpluginの仕組みとして、1chunkずつ流れてきて、それをoutputする、という仕組みになっており、chunkはfluent-bitでハードコートされています。output側でまとめられるとよいのですが、fluent-bit-go自体にそのような仕組みがなく、それを利用しなければならない上記のpluginではS3へのアウトプットを溜める、ということができません。Chatworkでは、S3に集めたあとにAthenaで分析するようにしているのですが、fluent-bitから送られたログでは大量の小さいファイルができ、Athenaが全然使えない(クエリが終わらない)状態になってしまいました。
fluentdをaggregatorとして導入
fluent-bit単体で上記の問題を解決することができなかったため、fluent-bitをforwarder、fluentdをaggregatorとして、S3へのアウトプットはfluentdのところでまとめるようにしました。 現在ではfluent-bitにS3 pluginがあるので、直接大きなファイルを送ることもできますが、ChatworkではSPOTインスタンスを多用しており、ノードの入れ替えなどが比較的多いので、各ノードに大きめのBufferを作るのはやや効率が悪く、aggregatorであるfluentdを、StatefulSetで運用し、バッファをPVで永続化して運用するのが効率的、かつ、大きなロストがない、と判断して、現在でもこの構成にしています。
fluent-bitの設定
各ノードにいるfluent-bitですが、Chatworkではバッファとしてメモリしか使用していません。これではfluent-bitの再起動時などにロストしたり頭から読み込んで、2重で送られるのでは?と思われると思いますが、その通りであり、それを許容しています。もちろんできるだけ小さいほうがよいのですが。
Chatworkのアプリケーションログは1ログもロストしてはいけない、という要件ではなく、あくまで後の調査などで傾向を掴むんだりエラーメッセージを確認したり、という利用がほとんどです。
fluent-bitの導入当初はディスクのバッファ + DBにしていましたが、これだけのログ量なので、hostPathでマウントしてバッファとして利用しているノードのディスク負荷が高く(tailのDBの更新が特に)、他のPodにもやや影響があるような状態でした。また当時はディスクバッファが原因不明で壊れやすく、壊れてしまうとOOMループに陥ったり、ホストに入ってバッファを消さなければいけない、など、いったん発生すると厄介な状況でした。 導入当時よりfluent-bitのバージョンがかなり進んでいるので、当時よりは壊れにくいとは思いますが、vectorのドキュメントを見ると、壊れることがあるようです。
これらを経験して、現在の構成としてはログ周りのリスクとして、少し欠損する可能性がある + 重複することがある、を許容している状態です。 そのため、1件しか発生しなかったエラーメッセージはタイミングによっては捕縛することができないかもしれませんが、全体のリクエスト量に比べて極々稀なパターンに対応するための構成にするにはコストが高いと判断しています。
また、実際にロストするパターンが、実際には起きにくい、というのもあります。 具体的には、Podの再起動などfluent-bitが再読み込みをしている最中に(fluent-bitはメモリバッファがいっぱいになると適宜pauseしてくれます)、aggregator側に問題があって、fluent-bitから送れないままノードが終了してしまう、というようなパターンです。 ノードが突然死するようなパターンもロストする可能性が高いですが、それはhostPathでディスクにバッファしている場合でも同様です。
このあたりは要件が変われば、また変わるところではあり、ログ周りの運用の難しいところです。
fluent-bitはtailなどのpositionの位置を保持するのに、SQLiteを使用してしまう都合上、大量のログがある場合には、ディスク負荷が高くなりやすい、という問題があります。
また、fluentdとは違って、total_limit_sizeのようなオプションがなく、間接的にバッファへの溜め込みを制限するしかないので、ディスクをバッファとして使う場合の運用が難しいような気がします。
fluent-bitですが、下記のようなリソース状況です。

fluentd時代は768MiでOOMが発生していましたが、fluent-bitはこのメモリ量で安定しています。
まとめ
ChatworkにおけるKubernetesのアプリケーションのログ収集に関して、背景、変遷、現在の構成に関して記載しました。 vectorも結構気になっていますが、現状ではこの構成で大きな問題がないので、気になる、で留まっています。