今回はEKSでDNSを安定させるために対応した話を書きたいと思います*1。
- 一定数のPod以上になるとサービスが不安定になる
- conntrack溢れの犯人はkube-dns(CoreDNS)
- conntrackのmaxを増やす
- kube-dnsのautoscale
- node-local-dnsも入れる
- node-local-dnsを入れた途端にDNSまわりが再び不安定に
- node-local-dnsの利用ポイント@EKS
- 無事に安定
一定数のPod以上になるとサービスが不安定になる
Chatworkでは、2020年にEC2で動かしていたレジェンドシステムをEKSに移行しました。 その移行の際(EC2側とEKS側でRoute53での重み付けによる並行稼動しながら)、ある割合以上のリクエストをEKS側に流すと、途端に不安定になる状態になりました。
調べてみると、一部のノードでconntrack tableが限界突破して、アプリケーションへの接続がDropされている状態でした。
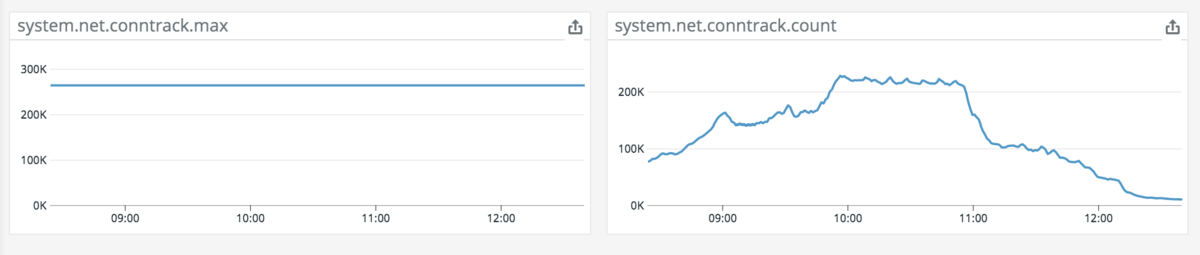
conntrack溢れの犯人はkube-dns(CoreDNS)
conntrack tableを調べてみるとCoreDNSが多いことが判明。この時はEKSのデフォルトの2Podのままで動かしていたので、一部のCoreDNSにリクエストが殺到、conntrack tableが溢れている状態でした。
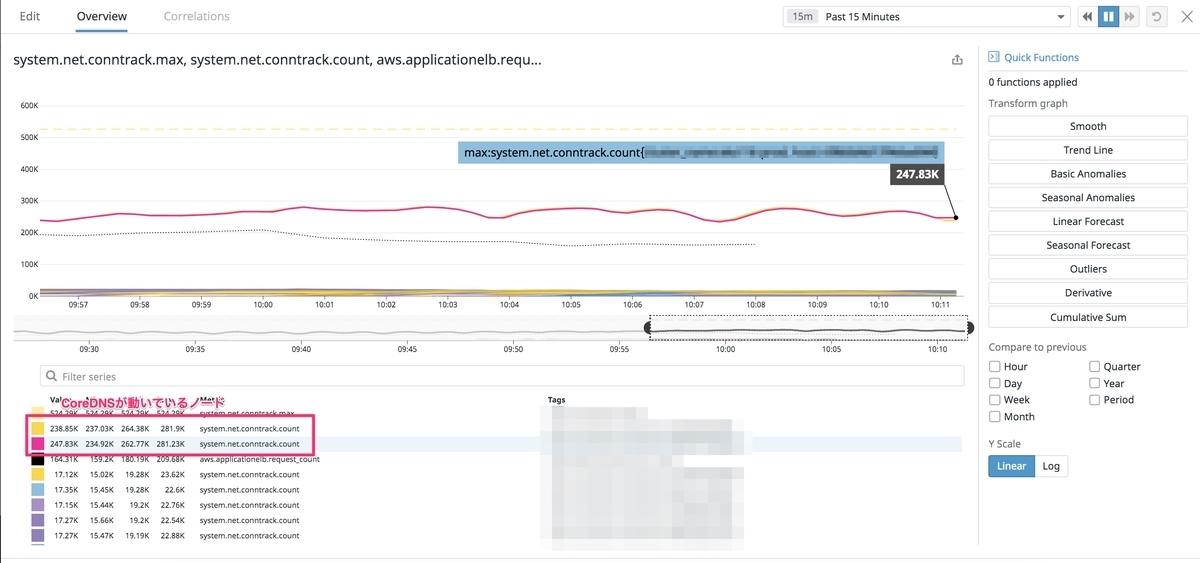
conntrackのmaxを増やす
溢れているんだから、まずは増やそう!ということで、調べてみるとデフォルト値とは異なる値が設定されていることを確認。kube-proxyが設定していたことがわかったので、kube-proxyの設定を変更して、増やす対応をしました。
conntrack:
max: 0
maxPerCore: 32768
min: 131072
tcpCloseWaitTimeout: 1h0m0s
tcpEstablishedTimeout: 24h0m0s
のmaxPerCoreのところです。
kube-dnsのautoscale
同時に導入したのが、dns-autoscalerです。
正確には入れるのを失念していた、というのが正しいです(恥ずかしい話ですが)。
レジェンドシステムは最初からEKSのKubernetesで稼働させていますが、それ以外のKubernetesアプリケーションはkube-awsで作成したクラスタで稼働していました(現在はEKSに移行済みです)。
そのkube-awsでは、dns-autoscalerが始めから入っているので、存在は知っていたものの、EKSへの導入を失念していました。 その結果として、CoreDNSは2Podのままで動いていたことで、リクエストが集中し、当該ノードのconntrack tableが溢れていましたが、2PodのCPUもパツパツでした。
dns-autoscalerを入れて、CoreDNSがある程度のPod数になると劇的に安定しました。
node-local-dnsも入れる
これで大体安定したのですが、CoreDNSのPodがいなくなるときに(Chatworkのノードグループはフルスポットインスタンスなのである程度ノードが入れ替わる)、アプリケーションでDNSのエラーが発生していました。
これは、inflightなDNSリクエストが、CoreDNSの退去によって、エラーになってしまうことが原因のようでした*2。
そこで導入したのが、node-local-dnsです。
これは各ノードにDamonsetとして入ります。そのためノードがいなくなる場合も、最後まで残り、CoreDNSのPod退去による影響はなくなります*3。 また、node-local-dnsを導入することで、クラスタ全体のDNSリクエストを減らしたり、CoreDNSが動いているノードのconntrack tableをさらに減らしたい、という効果も期待していました。
node-local-dnsを入れた途端にDNSまわりが再び不安定に
上記のドキュメントにあるマニフェストをえいやっとapply(もちろんtest, stgで動作確認はしてから)した途端、リクエストが圧倒的に多い本番環境ではDNSまわりが再び不安定になりました。node-local-dnsのログを見てみるとtimeoutが頻発していました。設定ファイルには問題ないし、一体どこが原因なんだ...と思ったら、EKSでnodel-local-dnsを利用するときには、force_tcpを使ってはいけない、というものでした。
node-local-dnsの利用ポイント@EKS
下記のAWSのドキュメントではnot recommendですが、外すだけではなくて、prefer_udpにしたところ安定しました。
When running CoreDNS on Amazon EC2, we recommend not using force_tcp in the configuration and ensuring that options use-vc is not set in /etc/resolv.conf
どうやらEC2(nitroベース)の制限で、dns over tcpだと同時接続数が2までしか対応してないようです。
We have identified the root cause as limitations in the current TCP DNS handling on EC2 Nitro Instances. The software which forwards DNS requests to our fleet for resolution is limited to 2 simultaneous TCP connections and blocks on TCP queries for each connection
https://github.com/aws/amazon-vpc-cni-k8s/issues/595#issuecomment-658635050
そしてもう1つ。 eksctlでは、kubeletが設定する、各コンテナのdnsの向き先を変える設定がありますが、node-local-dnsを利用する場合、この設定は不要(つまりkube-dnsのままでOK)です。
これはnode-local-dnsが起動時にdummy deviceとiptablesを作成して、kube-dnsへのリクエストを自分に向けるようにするためです。
この仕様を理解していなかったために、入れただけではnode-local-dnsは使われない(eksctlでDNSの向き先を設定したノードグループを作るまでは使わない)、と思っていたので、上記のようにtimeoutが頻発した際はとても焦りました。
参考までに、node-local-dnsのproposal(本家にもあったんですが、いつの間にか削除されており、参考URL)と最終版と思われるkeps、あとはdummy deviceを作成するあたりの処理のリンクを記載しておきます。
https://github.com/kubernetes/enhancements/blob/master/keps/sig-network/0030-nodelocal-dns-cache.md
このdummy deviceのおかげで、node-local-dnsのupdate時など、node-local-dnsが一時的に使えない場合は、アプリケーションのDNSのリクエストはCoreDNSへ直接リクエストされるようになり、クラスタ全体の可用性が上がります。
無事に安定
ということで、
- dns-autoscalerを入れる
- node-local-dnsを入れる
- ただしEKSでは
force_tcpは使わない
- ただしEKSでは
の2つでDNSは無事に安定しました。
DNSが不安定だったころ、DNSへの問い合わせがブロックになっていて、無駄にPodの台数も増えていました。 Pod数の適正化、という観点からもDNSの安定は重要です。
ということでEKSのDNSまわりでお困りでしたら試してみて下さい。