This time, I would like to talk about how I fixed DNS errors on EKS (Chatwork's EKS is operated using a single multi-tenant cluster)
- Service becomes unstable when the number of pods exceeds a certain number
- Culprit of conntrack overflow was kube-dns (CoreDNS)
- Increasing the conntrack max value
- autoscale kube-dns
- Deploy node-local-dns too
- DNS-related services started to become unstable again once node-local-dns was deployed
- Points to use node-local-dns on EKS
- Stabilized at last
Service becomes unstable when the number of pods exceeds a certain number
At Chatwork, we migrated the Legend system which was run on EC2 over to EKS in 2020.
During that gradual migration (with parallel EC2 and EKS operation using Route53 weighted routing to both services), it suddenly became unstable when more than a certain ratio of requests were routed to EKS.
A closer examination revealed that the conntrack table of certain nodes had filled up, causing the connections to the application to drop.
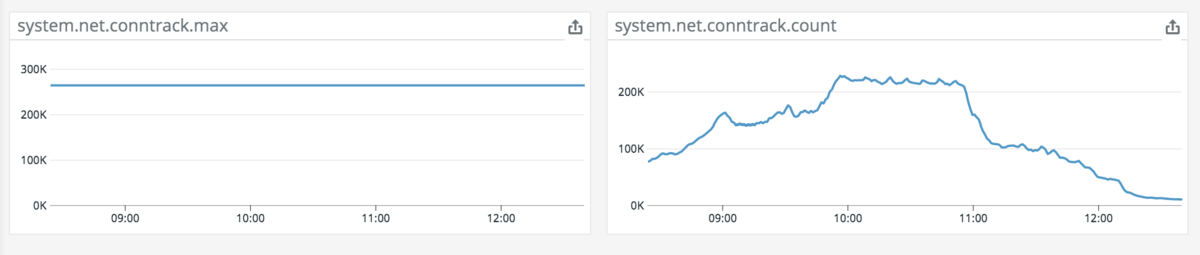
Culprit of conntrack overflow was kube-dns (CoreDNS)
A closer look at the conntrack table revealed that there were a lot of CoreDNS. As they were operated with the EKS default of 2 Pods at the time, part of the CoreDNS was getting too many requests, causing the conntrack table to overflow.
Increasing the conntrack max value
So it's overflowing, let's try increasing the maximum value! That's what I first figured, and I found that a non-default max value was set. I found out that kube-proxy was overwriting that value, so I changed the settings for kube-proxy and increased the max value.
conntrack:
max: 0
maxPerCore: 32768
min: 131072
tcpCloseWaitTimeout: 1h0m0s
tcpEstablishedTimeout: 24h0m0s
It's the maxPerCore value.
autoscale kube-dns
At the same time, I also deployed dns-autoscaler. kubernetes.io
Actually, I forgot to deploy it (, embarrassingly).
The Legend System was running on Kubernetes through EKS from the beginning, but the other Kubernetes apps were running on clusters created by kube-aws (all of which have now been successfully migrated to EKS)
On kube-aws, dns-autoscaler is deployed by default, so while I knew of its existence, I had forgotten deploying it on EKS.
As a result, the CoreDNS was operating with the default 2 Pods, received a flood of requests, and overflowed the given node's conntrack table, so both the 2 Pods and CPU were overloaded.
Deploying the dns-autoscaler increased the number of CoreDNS Pods to a decent number and dramatically stabilized the system.
Deploy node-local-dns too
This largely stabilized the system, but a DNS error occurred on the application when a CoreDNS Pod is terminated (Chatwork's node groups are all Spot Instances, so some of the nodes will swap from time to time).
This error appears to occur when there are still pending DNS queries when the CoreDNS pods are terminated (I did not check the entire log, but the timing led me to believe that this was what happened.)
So, I went on to deploy node-local-dns. cloud.google.com
This is deployed as DaemonSet on each node, staying until the end when a node is terminated and eliminates the disruptions caused by the CoreDNS Pod swap (Of course, errors between node-local-dns <-> CoreDNS could still occur in this setup).
Additionally, I expected that deploying node-local-dns would reduce the number of DNS queries for the whole cluster and further reduce the load on the conntrack table running on the CoreDNS nodes. But...
DNS-related services started to become unstable again once node-local-dns was deployed
Right after I applied the manifest in the document above (after testing its operation on test, stg, of course), the DNS-related services started to become unstable again on the working environment which needs to process a comparably huge amount of queries.
Checking the node-local-dns logs showed that timeouts occurred frequently. As there were no issues with the settings file, I was wondering what the reason was...and realized later that force_tcp shouldn't be used when deploying node-local-dns on EKS.
Points to use node-local-dns on EKS
While it is noted only as "not recommended" in the following AWS document, I not only disabled it but also changed it to prefer_udp, which fixed it.
When running CoreDNS on Amazon EC2, we recommend not using force_tcp in the configuration and ensuring that options use-vc is not set in /etc/resolv.conf
It appears that EC2 (Nitro system) limits the number of simultaneous connections to 2 for DNS queries over TCP.
We have identified the root cause as limitations in the current TCP DNS handling on EC2 Nitro Instances. The software which forwards DNS requests to our fleet for resolution is limited to 2 simultaneous TCP connections and blocks on TCP queries for each connection
https://github.com/aws/amazon-vpc-cni-k8s/issues/595#issuecomment-658635050
Another thing to note.
On eksctl, there is a setting that allows you to change the destination of each container's DNS, but it is not necessary to configure this when using node-local-dns (in other words, it is OK to leave it as kube-dns).
This is because the node-local-dns creates a dummy device and iptables and when it runs, directing queries to kube-dns to itself.
As I did not know about this specification, I assumed that simply deploying it would not use node-local-dns until I create a node group that configures the DNS destination on eksctl, so I was confused when the timeout described above kept on occurring.
As a reference, here is the link that explains the node-local-dns proposal (it was on the original page before, but got deleted suddenly, so just the URL for reference), presumably the final KEPs, and how it creates a dummy device.
https://github.com/kubernetes/enhancements/blob/master/keps/sig-network/0030-nodelocal-dns-cache.md
Thanks to this dummy device, when the node-local-dns is updating or is temporarily unavailable, the DNS queries on the app is directed to CoreDNS, which improves the availability of the whole cluster.
Stabilized at last
In conclusion,
- Deploy dns-autoscaler
- Deploy node-local-dns
- But disable "force_tcp" if on EKS
These 2 steps successfully fixed the DNS issues.
When the DNS was unstable, the queries to the DNS were blocked and the number of pods was increased unnecessarily.
So, a stable DNS server is also essential to optimize the number of Pods.
Please try this out if you have any issues related to DNS on EKS.