SRE部の坂本です。
みなさま、Kubernetes環境(EKS環境)におけるアプリケーションのログ収集ってどうされていますか?
Chatworkでは下記のように各ノードのforwarderとしてfluent-bit、aggregatorとしてfluentdというfluent兄弟を両方使っており、やや珍しい構成のように思えるので、そのことについて記載したいと思います。
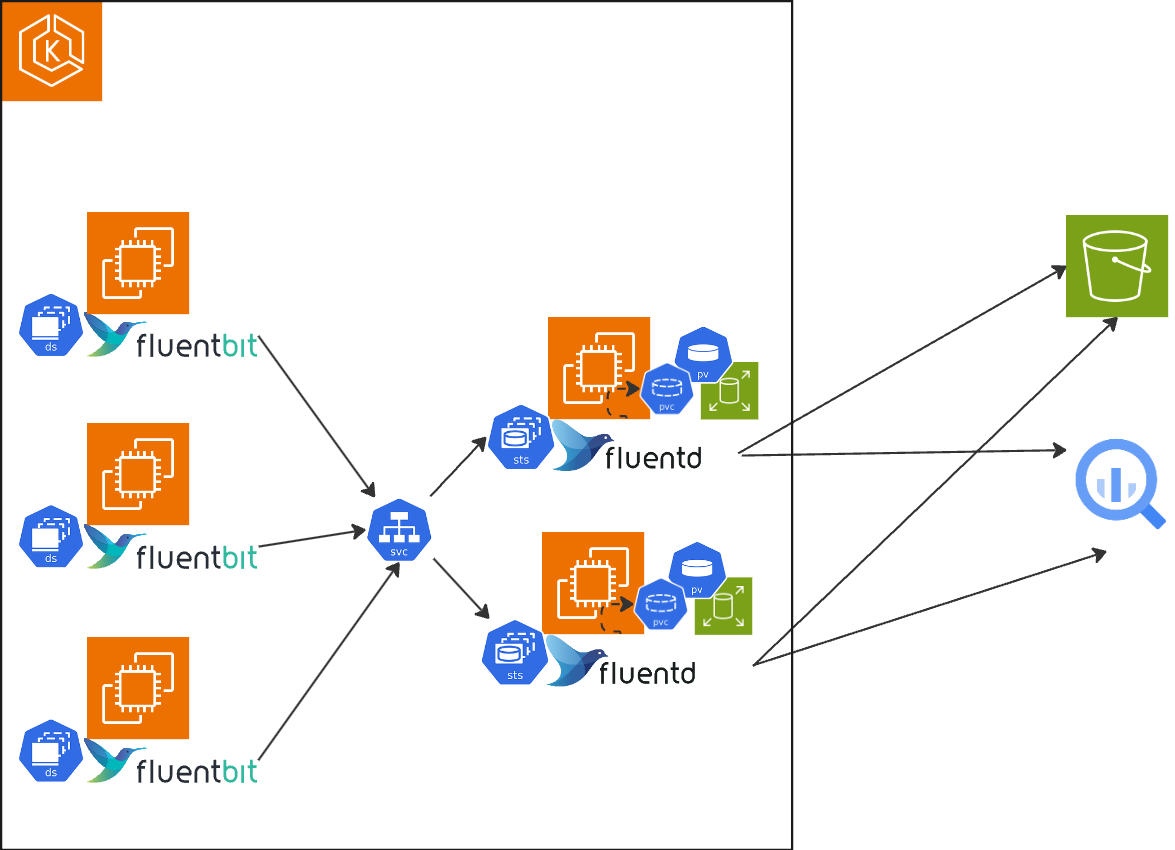
この構成にしたのは、2020年*1ではありますが、それほど古い考えではないように思えるのと、ふと構成を振り返ったときに、内部にも全体をまとめたドキュメントがなかったので、外部発信しつつまとめたいと思います。
Chatworkのアプリケーションログの量
具体的な数値を乗せることはできませんが、アクセス数やログの量は多いです。
アプリケーションのログの量は、アクセス量に比例(というわけでもないけど、基本的には)するわけですが、Chatworkのアクセス量は、2024年5月において、ピーク時で?M req/min(1桁台のメガ(M))あります。これは秒間に直すと、??K req/sec(2桁台のキロ(K))ぐらいです。ChatworkのアプリケーションはCloudFront -> ALB -> Pod(nginx + php-fpm)で、このリクエスト数はALBなので、すべてがアプリケーションのためのリクエストではないにしても、とにかくそれぐらい流れています。
nginxでアクセスログが出てきますが、これが特に多いです。
Athenaで集計してみると(database名、table名は実際のものではないです)、
SELECT count(*) FROM "database"."chatwork-web-nginx-accesslog" where dt = '20240519' ;
-> 2億レコード弱あります。1日で。これはnginxだけのログです。 なので、2億 / 86400 = 2314.81481 ということで、1秒で2300レコードぐらい吐き出されています。
これは1日の平均です。ピーク時はもっと出ています。
Chatworkのアクセスパターンは、Chatworkのユーザ層が国内のToB向けということもあり、平日日中に多く、夜間はだいぶおとなしいです。 平日日中と夜間の差はだいたい35倍ぐらいです。
アクセスが増えればPodもオートスケーリングしますが、PodのCPU使用率でのスケールなので、正比例に増えるわけでもなく、1Podあたりのリクエスト数がピーク時には増えます。
fpmのほうは
SELECT count(*) FROM "database"."chatwork-web-php-fpm-log" where dt = '20240519' ;
-> 1000万レコード以上あります。nginxに比べると少ないものです。
10000000 / 86400 = 115.740740741 ということで、1秒で100レコード以上吐き出されています。 こちらも1日の平均です。
さらに1ノードに1Podではなく、1ノードにこれぐらいログを出すPodが複数います。 下記は本番のあるノードのPodの一部ですが、kddi-webというのはKDDI Chatworkのことで、諸事情により、通常のChatworkとは別Podで動いていますが、中身は同じで、こちらもまずまずの量のログが出ています。
$ kubectl get po -n chatwork-web -o wide | grep ip-10-1-111-11.ap-northeast-1.compute.internal chatwork-web-php-7c9b75b8dc-aa111 2/2 Running 0 75m 10.1.123.58 ip-10-1-111-11.ap-northeast-1.compute.internal <none> 1/1 chatwork-web-php-7c9b75b8dc-a11abc 2/2 Running 0 73m 10.1.124.4 ip-10-1-111-11.ap-northeast-1.compute.internal <none> 1/1 kddi-web-php-68db945c97-b3fa1 2/2 Running 0 73m 10.1.129.247 ip-10-1-111-11.ap-northeast-1.compute.internal <none> 1/1
このノードにはアプリケーションのPodのほかに、Daemonsetも複数動いており、それらのすべてのログを収集し、可能な限り欠損しないようにaggregatorに送信できるパフォーマンスがforwarderには求められます。
kubelet側での設定で重要なこと
やや脱線しますが、EKSのノードのkubeletにおいて、コンテナのログのローテションまわりは変えていますか?
コンテナのログのローテーションに関連する項目は下記の2つです
- containerLogMaxSize
- ローテーションされるサイズ。デフォルト: 10Mi
- containerLogMaxFiles
- ローテーションの世代。デフォルト: 5
- containerLogMaxWorkers(1.30から)
- ローテーションの同時実行数。デフォルト: 1
Chatworkではノードのuser_dataにおいて、jqでpatchを当てて、設定を変えています。 やや涙ぐましいシェル芸感があり、実際にはこの2つの項目以外にもpatchを当てているところがあり、もう少しワンライナーが長いです。
ファイルをわけているのは、これらを試すときに別ファイルのほうがデバッグしやすかった、というのがあります。
# kubelet
cat /etc/kubernetes/kubelet/kubelet-config.json | jq ". |= .+ {\"containerLogMaxSize\": \"${WORKER_LOG_MAX_SIZE}Mi\",\"containerLogMaxFiles\": ${WORKER_LOG_MAX_FILE}}" > /tmp/kubelet-config.json
mv /tmp/kubelet-config.json /etc/kubernetes/kubelet/kubelet-config.json
このようにして、ChatworkではcontainerLogMaxSizeを本番では500Mi, containerLogMaxFilesを2としています。 なんで512Miにしなかったんだろう...と過去の自分に聞いてみましたが、わかりませんでした。とにかく、それぐらい大きくしています。ローテーション時の負荷を考えるともう少し小さくてもよい気もします。
上記に記載したログの量なので、デフォルトの10Miではすぐにローテションされてしまいます。
まとめ
Chatworkのログがかなり膨大であることを記載しました。
(2)では、現構成の前に使っていたものや、この構成にした理由(だいたい書きましたが)について記載します。
*1:ChatworkのモノリスアプリケーションがEKSに移行したとき https://creators-note.chatwork.com/entry/2020/11/04/141050