どうも。ご存じ、サーバーサイド開発部(PHP)のやまざきです。
『優れた UX は心地のよい Developer Experience から生まれてくる』と信じて20余年。今年は最高な年になりそうです。
さて本ブログの本題ですが、ある程度のサービス規模になってくると運用・保守は大変になってきますよね。今日は昨年2021年にサーバーサイド開発部(PHP)としてのサービス監視体制を改善していったよ、って話をふりかえりながら書こうと思います。
目次
- 目次
- Chatworkのサーバーサイド運用・保守体制
- バックエンドで利用中のシステム監視SaaS
- バックエンドのアプリケーションログ基盤
- サーバーサイド開発部(PHP)としてのサービス監視体制の課題(2021年)
- PHPエラー撲殺部発足
- エラー通知をスルーしないためにしたこと
- 2021年のPHPエラー撲殺の成果
- PHPエラー撲殺部からの学び
- さいごに
- やまざきの過去記事
Chatworkのサーバーサイド運用・保守体制
Chatworkはビジネスインフラを担うようなサービスとなることを目指しています(参考記事)。
そのためには24 時間365日、可能な限り安定したサービスを提供する必要があります。而して、Chatworkのエンジニアはサービスの稼働状況を監視し、問題があればいち早く状況を改善するよう動くことが求められます。
何を使いどういう体制で運用保守を行っているかを簡単に説明させて頂きたいと思います。
バックエンドチームでの基本的な運用・保守体制
Chatworkの開発組織全体を統括するプロダクト開発本部配下においてバックエンドを担う部署は、2022年1月現在
- SRE部
- コアテクノロジー開発部
- サーバーサイド開発部(Scala)
- サーバーサイド開発部(PHP)
があり、ぞれぞれの部署が責務を負うシステム範囲を運用・保守しています。各部署ごとに適時メンバーをチームに分割して活動している感じになります。
たとえば、やまざきの所属する 「サーバーサイド開発部(PHP)」では、「SuperNova チーム」や「プロダクト改善チーム」のように目指すべきプロダクト指標を達成できる最適なチームを適時編成して活動しています。
バックエンドで利用中のシステム監視SaaS
サービスの稼働状況を把握したり、問題に関する情報の通知を受けるためにメインどころで下記の監視SaaSを導入しております。
Datadog
サービスの稼働状況を組織の関心事に沿ってダッシュボードを作って監視しています。サービス全体、マイクロサービス単位、インフラグループ単位など。
またそれらのメトリクス変化に従ってアラートを通知しています。
New Relic
こちらは主に PHP で構築されたシステムの APM 監視のために導入しています。Datadog の APM という選択肢もありましたが、諸般の要件で New Relic の APM を採用しています。
APM に重点をおいているのでパフォーマンス改善や問題発生時の真因究明、深掘りに使うことが多いといった印象です。
バックエンドのアプリケーションログ基盤
ここではアプリケーションログをどのように蓄積しているのか、そして問題のあるアプリケーションログをどのように検出してるのかを簡単に説明します。
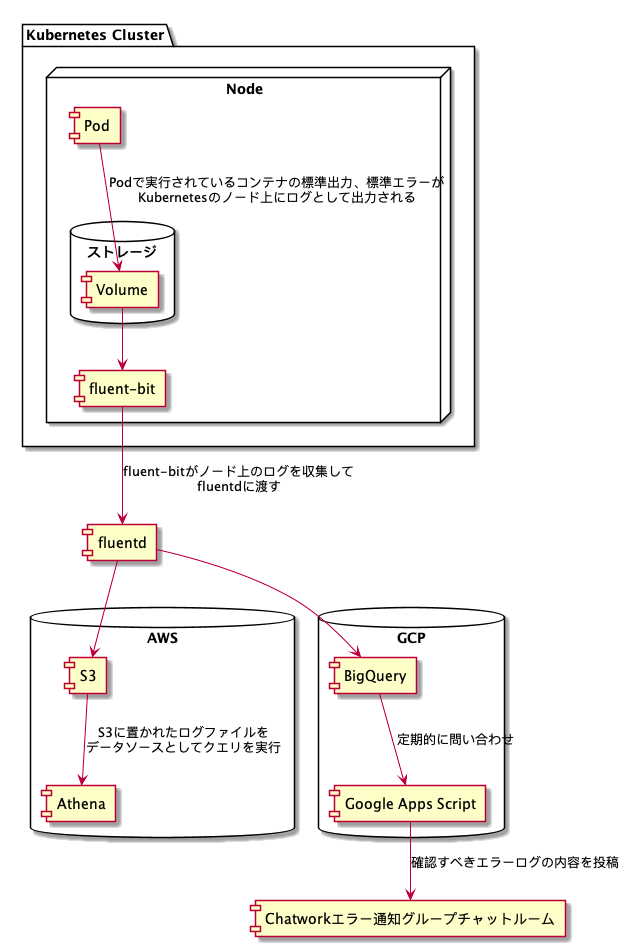
バックエンドでのアプリケーションログ収集のデータフロー
上図をご覧ください。
- Pod で実行されているコンテナの標準出力、標準エラーが Kubernetes ノード上にログとして出力される
- fluent-bit がログを収集して fluentd に渡します
- fluentd は収集したログを S3 と BigQuery にログデータを S3, BigQuery にアウトプットします
PHPシステムでのアプリケーションログの通知
アプリケーションログは、PSR-3: Logger Interface で定義されているログレベルをログメッセージに付与し、フィルター条件として活用しています。
BigQuery に蓄積されているアプリケーションログデータを Google Apps Script を使って定期的にエラーを通知するようにしています。その時のフィルター条件としてログレベルが info より上のログレベルを通知するようにしています。
サーバーサイド開発部(PHP)としてのサービス監視体制の課題(2021年)
2021年上期当時は監視SaaS、アプリケーションログからの通知を各々PHPエンジニアが判断し、問題なければ「対応不要」として暗黙にスルーするという運用をしていました。
スルーするぐらいなら恒久対策をすればいいのですが、なぜそれが行われなくなるのでしょうか。ちょっと極端な妄想をしてみました。
エラーがスルーされていく仮想シナリオ
- チームはモノリスのシステムを開発している
- 開発案件はプロジェクトチーム形式で、プロジェクトチームの結成、解散の繰り返されている
- プロジェクトチームの解散後、当時の開発メンバーがボランティアベースでエラー対応、保守を行う
- 所属部署の移籍するとき運用知識の移管は行われない
- 所属移籍後のチームでの活動が忙しくなると、ユーザー影響のないエラーログはスルーされて、根本対策は行われなくなる
- 更にそのプロジェクトに従事したエンジニアが退職すると運用知識は失われる
- 定常的にエラーがでている状態になる
- チームに新しくジョインしたメンバーはモノリスなリポジトリへのアクセス権を得る
- チームに新しくジョインしたメンバーは自分が触ったコードには責任を持とうとする
- チームに新しくジョインしたメンバーはあるタイミングでエラー通知を受け取る権限を得る
- チームに新しくジョインしたメンバーは過去に何度も通知されているエラーの経緯を理解できず、通知内容に対する行動を起こせない状態のままである。本当に重大なエラーは開発した担当者がみているのだろうと暗黙の期待をかけている
- チームに新しくジョインしたメンバーはモノリシックなコードベースに恐怖心をもっており、問題を根本的に修正したほうがいいと思ったとしても対応を先延ばしにしてしまう
- エンジニアたちは、本当に深刻なエラー通知は誰かが監視しているだろう、と互いに暗黙の期待をかけるようになる
- その中でも発生頻度の高いエラーは、社歴の長いエンジニアでも緊急度判断を誤ることがある。「いつもでている」という予断は正しい判断を阻害する要因になる
- 重大なエラーが本番環境で起こる
これはやまざきの妄想です。ですが、やまざきにとっては現実感を伴って迫ってくるものがあります。
空想にせよ妄想にせよ、想定される最悪のシナリオが起こらないようにを少しでもカイゼンできないかと思い「PHPエラー撲殺部」という部活を発足させました。
PHPエラー撲殺部発足
組織パターンに「防火壁」があります。
外部からの影響や特別に関心を持ったグループによって開発者が妨げられないようにしたいと思ったら、防火壁を立てて(たとえばマネージャー)、「ペストを寄せ付けない」ようにしよう。
サーバーサイド開発部(PHP)メンバーである自分が、ソロメイン活動の体制となったので誰にコミットメントしたわけではないですが「防火壁」を自認して、「エラー監視/対応」からスクラムチームを守る振る舞いをしてみようと思いました。
組織開発の観点で自分は経験が浅いところもあり、組織パターンのフィールドワークによってチームやチーム間のフォースに変化があるのか、それとも何も変わらないのか、観察してみようという個人的な興味もあったのは事実です。
さて、そこで「PHPエラー撲殺部」という部活を立上げ、PHPエラー通知を倒しはじめてみました。
エラー「撲滅」という穏やかなワードではなくエラー「撲殺」というパワーワードを採用したのは、過去の有志たちが幾度もエラーを撲滅しようとして達成できなかったという経緯を知っていたからです。エラーを殺るか、エラーに殺られるか、その二者択一、この戦いに引き分けはない、そんなの覚悟をこめた命名でした。(やまざきが勝手に妄想して命名しただけです)
自分がエラー監視/対応に詳しくなる
そもそも、エンジニアがスルーしていたエラー通知とはどのようなものだったのでしょう。それをつぶさに観察することから始めました。それらは大別すると下記のパターンでした。
- システムのメモリ不足
- ネットワークまわりでの通信失敗
- ファイルシステムのIOエラーやファイルシステムベースの排他制御失敗
- DBでのタイムアウト/デッドロック/ユニーク制限違反
- 外部サービスが正しく動作していない
- 冪等なバッチ処理で「処理済み」を前提条件を満たしていないとの警告が出る
- 入力バリデーションの不備によるランタイムエラー
平たくいうと、異常系の考慮漏れが大半でした。
エラー通知をスルーしないためにしたこと
以下のプラクティスは、これがどのような組織でも正しいというわけではなく、我々が抱えている課題にたいしてこのようなアプローチが解決に繋がるのではないか、という仮説を元に我々が実践した記録です。
何をエラーとして検知すべきかを再定義した
出力するログレベルのガイドラインを「運用保守担当者の対応優先度」を想定して定義しました。つまり、急ぎなのか、そうじゃないのかの緊急度指標としてログレベルを使うことにしました。
ログレベル:info
- エラーではない純粋な動作ログ
ログレベル:warning
- エラーとして通知される
- 次回リリースまでに対応すべき問題を検知している
ログレベル:error
- エラーとして通知される
- 1営業日以内に直すべき問題を検知している
ログレベル:critical
- エラーとして通知される
- 24時間/365日で即応する必要がある問題を検知している
エラー通知は誰かが確認するという暗黙の期待を止める
これは「エラー監視/対応」にオーナーシップを取り戻すためにやったことです。
通知されたエラーを確認する1次受けチームを決めました。1次受けチームメンバーはPHPアプリケーションレイヤーで起こるエラー通知をすべてJIRAチケットとして起票し、エラー対する対処ステータスを見える化したうえで、必ずユーザー影響を確認するようにしました。
誤検知も含めて、必要な対策は(スクラムチームを横断した)サーバーサイド開発部(PHP)のタスクとして、ソロ活動のなかで対策できる人がチケットをとって改修を進めていくようにしました。
エラーメッセージに書かれるべきガイドラインを作った
エラーメッセージには発生した事実と発生時に初動が起こせるような内容を記載することにしました。たとえば、このような感じです。
[error] ????でデータ不正によるエラーが発生しました。次のドキュメントを確認して調査・対応を開始してください。 https://internal-knowledge.chatwork.com/abc
形式知としてのドキュメントを残しておき、そのうえで分からないことがあっても気軽にチャットでヘルプを求めて良い、というワーキングアグリーメントをメンバー間で確認しました。
この保守シナリオで絶対的にカバーしないといけないことは深刻なエラーやその予兆を見逃さないことです。判断に自信がなければ気軽にチャットでヘルプを求めて良い、というワーキングアグリーメントは必須でした。
2021年のPHPエラー撲殺の成果
PHPエラー撲殺部の活動で 200 近いプルリクエストが作成され、リリースすることができました。1つ1つのプルリクエストは数行、数十行のものですが通知されるエラーログの量は激減しました。
通知されてきたエラーをみて、「あ、いつものか。じゃあ、スルー」という作業はなくなりました。あまりにも通知が飛んでこないので、もしかして通知用の Google Apps Script が死んでるじゃないかと不安になるほどでした。でも、そのぐらいに効果を体感できたということです。
逆の言い方をすると、それほどに我々はエラー通知の量に感覚が麻痺してしまっていました。
以下、PHPエラー撲殺の成果で個人的に良かったなと思う点を列挙します。
- エラー通知の頻度が下がったことで、たまにくるエラー通知に対する優先度判断は最優先になった
- 結果、初動までにかかる時間は大幅に短縮され、ユーザー影響をより少なくすることができた
- エラー通知が減ったことによりタスクスイッチングがなくなり、開発チームの生産性が向上した
- 「スルー」という運用していたエラー通知がなくなった。これにより、通知されるログは常に確認すべきというシンプルな運用になった
- 「スルー」という概念がなくなったことで、運用保守担当チームの知識量に左右されないほぼ一貫した運用保守品質を実現できた
- 運用保守でのオーナーシップを回復できた
- エラー対策のPRから学び、定常的なプロダクト開発でも「捕捉されていない例外」に対する視点、「エラーメッセージの内容」に対する視点などを注視するようになった
PHPエラー撲殺部からの学び
PHPエラー撲殺部は単に放置されていたエラー通知の根本対策をした、ということではなかったというのがやまざきの感想です。今回のカイゼンプロセスには多くの学びがあったと思っています。
むしろ、ムダがなくなって生産性がカイゼンしたというのは表面的な利益であると思っています。
学び1:「開発」「運用」「保守」は分けて考えられない
業界的に「運用・保守」という用語は「開発」とは区別されることがありますが、そもそもアジャイル開発においてはそのような区別はありません。「開発」「運用」「保守」はそれぞれに依存関係にあり区別することが合理的ではないからです。アジャイル原則のいう「価値のあるソフトウェアを継続的に提供する」とは、スプリントの成果物であるインクリメント(より良いであろうソフトウェア)を継続的に運用・保守し続けることだと言い換えることができます。たとえば「運用しやすさ、保守しやすさ」を考慮していないソフトウェアが、「継続的に価値を提供する」のが難しいということは容易に想像がつくと思います。
プロジェクトチームを作っての開発が必ずしも悪いことではないと思います。その場合でもアジャイルに適合させる必要があります。
その場合、最低限必要なのはプロジェクトの資産を適切に運用保守を担当するチームに引き渡すことです。プロジェクト資産を引き渡され運用保守をはじめるチームは、プロジェクトの WHY をはじめ、決定された ADR の読み合わせ、プロジェクトの WHY に合わせた効果測定のメトリックス確認方法、初期リリース時から直近の未来において「開発」「運用」「保守」がどのように変わっていくかの想定を含めた現在のアーキテクチャの説明を、プロジェクトチームから納得するまで引き出す必要があります。
前述のとおり、終結したプロジェクト資産を引き継ぐということは、引き継いだ担当者が運用保守だけ行うということではありません。PDCA の「アクション」に移ったタイミングで主管するエンジニアが交代しただけです。PDCA を高速に回し続け、プロジェクト成果物が提供する価値を最大化していく必要があります。
学び2:いつ負債を返すのか? という問いに真摯に応答する
予定外の割り込みタスクは、生産性に大きな影響を与えるということを誰もが直感的には分かっていると思います。
- ある作業Aから別の作業Bに切り替えるのにそもそも時間がかかる。なぜならどのような作業にも前提となる知識が必要であり、その知識を内部、外部記憶からロードする必要がある
- 前提条件が整ったとしても集中モードにはいるまでに最低でも15分はかかる
- 集中モードが解除されたあと、別作業の集中モードに移行するにはそもそも大きな「気持ちの切り替え」が必要となる
- スプリントプランニング外の割り込みタスクは「チームで合意したプロダクト価値を高めるスプリントのタスク」へ早く戻ろうとする心理的バイアスが働く。結果、割り込みタスクは恒久対策の詰めが甘くなる傾向がある。そしてプルリクエストなどへフィードバックが増え、結果対策をやりきれないなまま放置されやすい
これらは「中途半端に割り込みタスクをやらないほうがいい」という合理的な理由に思えます。しかし、問題解決を保留し根本解決を先延ばしにすることは「負債」となり常に利子を払い続けることになります。いま直さないものは、往々にしてその後も直しませんし、いざ直すとしても問題が露見したそのときよりも修正コストが高くつきます。
個人の感想ですが、借りたものを返さなくても良いのは小学生の引き算までです。そして恐ろしいのはソフトウェアの負債においても「複利の力」が働くことです。
さいごに
2022年02月現在「PHPエラー撲殺部」は有志の部活動から、サーバーサイド開発部(PHP)の正式な業務に昇格し運用されはじめました。
エラー通知に対して開発メンバーの意識も部活を始めると前と後では大きく変わりました。以前、エラー通知はマレに良く通知されてくるものでした。今では、エラー通知は本当にマレにくるものになりました。冗談みたいですが、本当のことです。そしてマレにくるバグを、開発メンバーは倒すようになりました。
前述の学びのとおり、エラー通知が減って生産性があがったというだけの単純な話ではないと思っています。運用保守の結果をそれだけにとどめることなく、開発プロセスにフィードバックしてより効率を高めていくという全体最適化能力の1つを手に入れたこと、結果プロダクト価値の最大化にチームがフォーカスできるようになったことが、この取り組みの最大のアウトカムだったのではないかと個人的には思います。
開発された機能を利用してもらうこと、それは運用保守フェーズによって実際にプロダクト価値が生まれはじめたということです。さらにそのフィードバックからプロダクト価値を向上させていく起点になります。ごく当然の話に聞こえるかもしれませんが、エンジニアは時にそういうことを忘れがちになってしまいます。誤解を恐れずいうならば、優れたアーキテクチャを備えたシステムを作ることだけが我々のゴールであってはいけないと思います。