はじめに
Chatworkで業務委託として働いている岩崎@sista05です。Chatworkではデータ分析基盤(DRE)チームに 所属してDagsterの導入、CI/CDやデータ環境の整備、ELT構築などを担当しています。
Chatworkでは、自社アプリをチャットアプリに留まらないビジネス版スーパーアプリとするべく開発を進めており、その実現にあたって全社的にデータの民主化を進めたデータドリブンな組織とするべく改革を進めています。
みっつさんの記事「プロダクトへの貢献を目指す、Chatworkの次世代データ分析基盤」で取り挙げたSnowflakeの導入を皮切りに、その後も継続的に改革を進めており、今回はChatworkのDREチームが特に各部門でデータを起点とした開発を滞りなく進められるような、DevOpsならぬいわばDataOpsチームとも呼べる体制として開発体制を改革している話をさせていただきたいと思います。
DREチームが抱えている問題
Chatworkアプリを先に挙げたビジネス版スーパーアプリへと進化させるにあたって、各部署間が自部署でデータを活用したい声が高まってきました。Snowflakeはデータのサイロ化を防ぐ要望に応えられるポテンシャルを持っているのですが、せっかくのデータ基盤を活用するために必要な運用体制や環境が十分に整っていない問題がありました。
具体的には、従来は各部門間でデータを利用するにあたってDREチームがその間に立って部署の要望に逐次応えていたのですが、この方式ではDREチームの負荷が高くなり度々ボトルネックが生じ、また、各部署でデータ利活用を進める必要があるにも関わらず開発もスケールしていかない悩みを抱えていました。
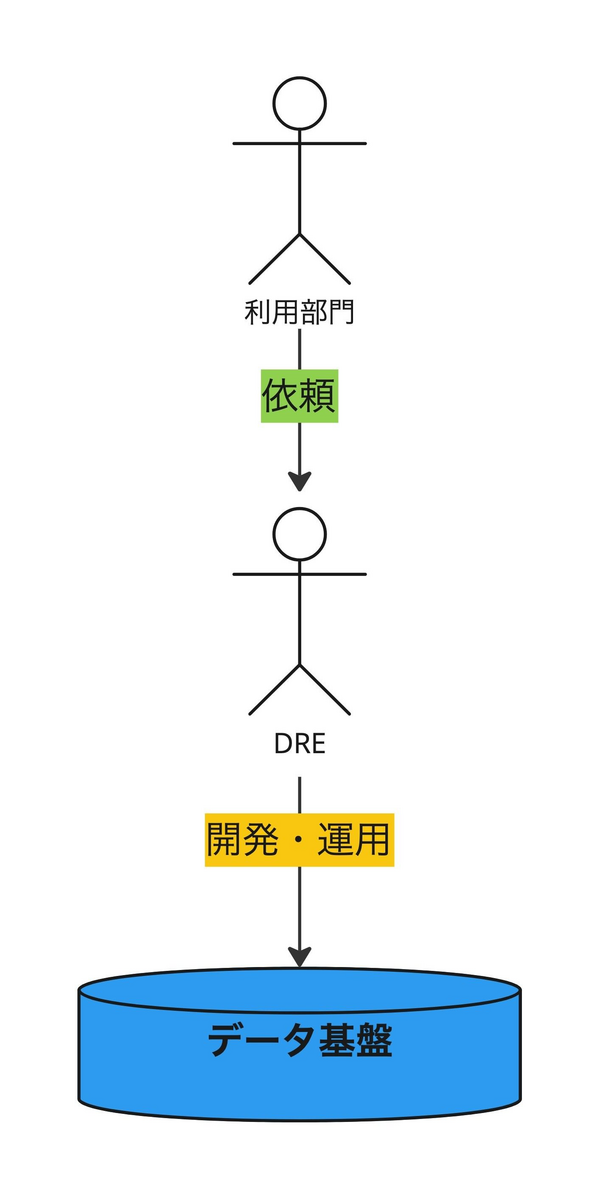
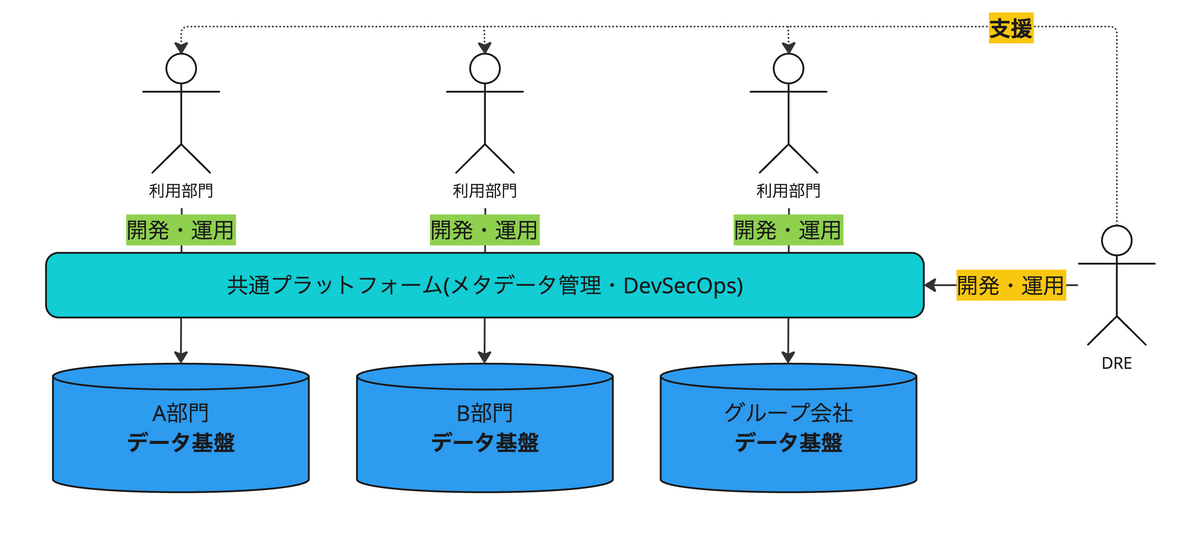
そうした背景を受け、これまでの開発をDREチームが請け負う縦列型の開発から、各利用部門が自分達でデータ分析基盤を整備できるよう分散開発・管理型並列型の開発体制へ移行を進める必要が出てきました。
DataOpsとは何か
このような取り組みは、一般的に指すところのDevOpsの方式が、データ分析を中心とした各部門との開発の中立ちをするところからDataOpsとも呼べる体制となっているのではと考えています。
DataOpsとは、Gartner社が最初に定義したデータ手法で以下のようなプラクティスを指します。言い換えれば、組織のビジネスプロセスに継続的なデータ分析を導入するための概念と手法と言えます。
組織全体のデータ管理者とデータ利用者の間における連携と、データフローの統合、自動化に焦点を当てた手法。それらは共同活用によりデータ管理のプラクティス(実践)を指す。
DataOpsという概念は日本ではまだ馴染みがなく先例もないのですが、今回は先駆的な取り組みとして広く知見を共有したく取り上げさせていただきました。ここからは、技術面、および組織面においてどのような改革をしているかいくつか例を挙げていきたいと思います。
取り組み1. Dagsterの導入
こちらのSplunkの記事に、DataOpsの中核となる技術について次のような記述があります。
DataOpsの中核となるのは、データフローを監視して制御する統計的プロセス制御と、運用システムを流れるデータを継続的に監視して検証するデータ分析パイプラインです
これを実現させるためには、データを専門としない人たちに対しても情報をわかりやすく共有し、かつ開発サイクルを高速に回すことが重要となってきます。そのためにChatworkでは全社のデータ連携を統合する手段として、データオーケストレーションツールであるDagsterを採用しました。
データオーケストレーションとは、複数のストレージからサイロ化したデータを取り出し、組み合わせて整理し、分析に利用できるようにするための自動化されたプロセスを指し、より詳細には以下の記事をご覧いただければ幸いです。
最近、Dagsterではビジュアライゼーションと組み込み機能の強化を進めており、特にdbtにおいては本家よりも強力なビジュアライゼーションを実現しています。Dagsterはviewerだけならユーザ無制限でデータの構成情報を閲覧することが可能であるため、全社でのデータ利活用にも大きく貢献するところとなるでしょう。
Dagsterのデータリネージ UI が強化されました。拡張可能なグループ、サイドバー、改良されたフィルター、改善された複数選択、クイック アクション、およびダーク モード テーマです。 https://t.co/aBnX3NP4ED
— akira @ DataMarket 💹 (@sista05) 2023年12月8日
また、Dagsterは各コンポーネントが疎結合でパイプラインを構成しており、各部署がコンポーネント単位での開発を可能とするデータメッシュ的な分散アーキテクチャを採用しています。そのため、一方の開発が他方の開発に影響を与えることなく開発サイクルを回すことができるので、ボトルネックを生じない特徴があります。
Dagsterの開発で工夫したことを一つだけ挙げさせていただくと、Chatworkではdbt CloudからDagsterへの乗り換えを試みているのですが、dbtはresult:errorやresult:failオプションを使用することで失敗したクエリやテストからリトライする機能があります。ですが、Dagster Cloudではdbtのrun_result.jsonを永続的に格納することができなかったのでresultタグによるリトライができなかった問題があり、この機能を実現するためにDagster CloudにEFS mountを実装する提案、協力をしました。
dbtの処理やテストはものによっては数分、数十分かかるものもあり、処理が失敗した場合にjobやopをイチからやり直すのは辛いシーンも出てくることがあると思います。それゆえ、ここは処理改善に大きく貢献できたところだと考えています。

取り組み2. フィーチャーチーム体制とDataOpsの融合
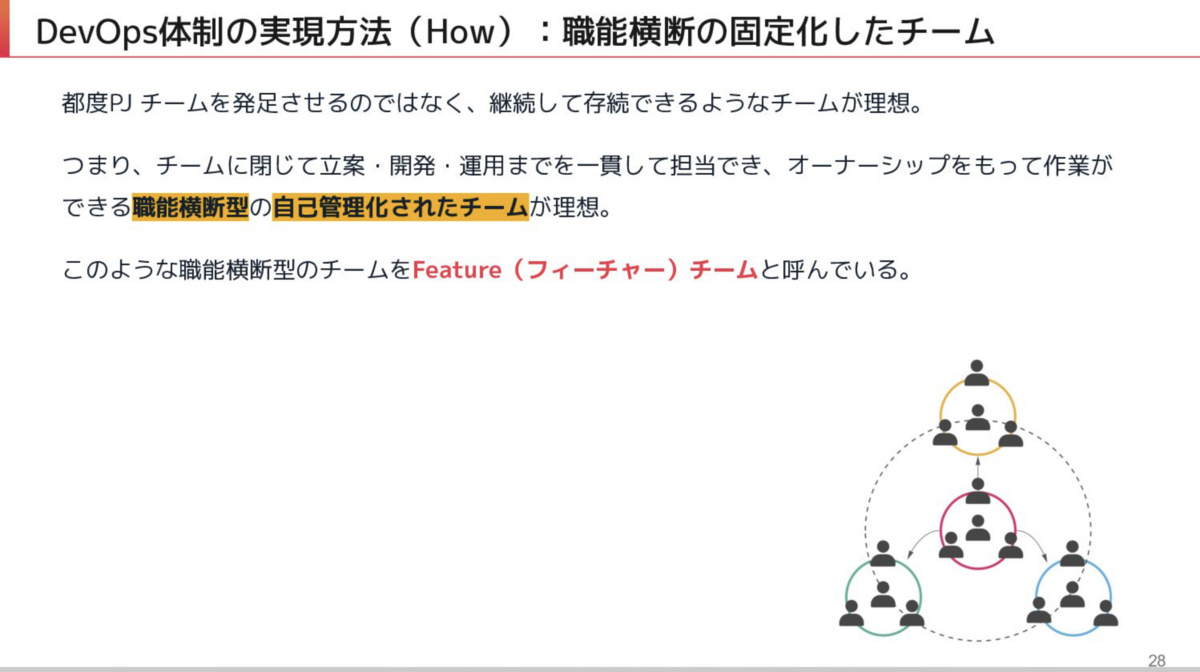
Chatworkでは、開発体制にフィーチャーチームの考え方を導入しています。 フィーチャーチームについては、12/3のつし@louvre2489さんの記事でも取り上げていただいていましたので詳細は以下をご覧いただければと思いますが、端的には、職能横断型で自己管理化したチームのことを指します。
DREにおけるフィーチャーチームの運用は、各部署からある程度開発の知見を持った人が一人二人開発チームに参画していただいて一緒に仕事をすることで開発のノウハウを継承し、ご自身の部署に戻っていただいてノウハウを少しずつ広めていく、ソフトランディングの方法論を採っています。
各部署に開発の知見をもつ人員を少しずつ増やし続けていくことで、部署内でのノウハウを蓄積しDREチームが各部署と連携を取る際のコミュニケーションコストを減らすことが可能になります。また、蓄積したノウハウを活かし各部署の人員も自律的に開発を進めていくことを目指しています。
フィーチャーチームの考え方と、横断的、早いサイクルで開発を進めるというDataOpsの考え方は親和性があり、将来的にうまく開発サイクルが回ることを期待しています。
取り組み3. トランクベース開発
フィーチャーチーム体制によりノウハウを蓄積した部署が開発を進めていくにあたり、その運用にはトランクベース開発の考え方を導入しようとしています。
トランク ベース開発とは、開発者が細かく頻繁なアップデートをコア「トランク」または main ブランチにマージするバージョン管理手法です。一般的には、サービス開発においてフィーチャーフラグなどと併せて、デリバリーサイクル構築と継続的な品質向上を目的とした手法ですが、この考え方をDataOpsにおいても採り入れたところが特徴的です。
具体的には、一般的なトランクベース開発における手法と同様ですが、迅速なリリースサイクルのためにCI/CDを強化し、CI/CDではデータモデルのテストやSnowflakeやDagsterなどの実環境へのデプロイ、dbt docsやelementaryなどによるデータの詳細情報や品質情報の全社展開、それら全てが自動化されたサイクルに細かい単位での開発であるトランクベース開発を差し込み、全体のサイクルに大きな影響を及ぼすことなくリリースサイクルを回し続けることを目指します。
まとめ
他にもまだまだ改善施策はございますが、私がこれは挑戦的だなと感じたところを取り上げさせていただきました。新しいモノを作り上げるために、まだ先駆者の少ないことに挑戦し続けなければいけないのは、これまでにない問題も立ちはだかってくるでしょう。それでも、こんな新しいことに挑戦していたんだな。ということは、色々な人の印象に残っていくのではないでしょうか。
そうして全社単位での改善サイクルを回し続ける姿勢の一端がDataOpsのような改善のサイクルにも現れていて、それはまだ名付けられていない無形の資産なのかもしれないということを考えながら締めたいと思います。