こんにちは。データエンジニアのみっつと申します。
技術基盤戦略室で次世代データ分析基盤プロジェクトを推進しております。
この記事はChatworkアドベントカレンダークリスマス前日の投稿です🎄
今回は本格的な利用拡大期を迎えた次世代データ分析基盤について、ステップアップを目指した開発体制の移行について書いて行きます📘
なお、最近参画いただいた@sista05さんから見た開発体制についても先日投稿いただいております。合わせてご覧ください 🙏
スモールスタートで始まったプロジェクトが拡大期を迎えて壁にブチ当たりました。壁を乗り越えてステップアップを目指す挑戦について語ります⛰️
スタート期
プロジェクトは自分1人での立ち上げから始まり、 ターゲットは、社内でも限られたユーザ(ビジネスを拡大するために高レベルのデータ分析が必要な部隊)に定めて、 従来のボトルネックを解消した新しいデータ分析基盤を素早く業務に活かせる形まで持っていくことを目指しました。
開発は少数精鋭で、リードする社員エンジニアは自分1人、手数が足りないところはデータ基盤開発やWebシステム開発に経験豊富な業務委託の方(最大4人)を集め、スタートしました。 合計で、2人+αくらいの開発リソースです。
下図のような開発体制です。

まずは開発が軌道に乗ることを目標に
新しく集まったメンバー、新しい技術を採用して、既存のデータ基盤から離れて新しい形へと作り変える野心的なプロジェクトのため、 速やかに開発を軌道に乗せる必要があると考え、以下を実現しながら進めました
Snowflake開発と相性がよいdbtをはじめとしたMDSを積極的に活用して、開発・運用工数をできるだけ圧縮した
開発環境をコンテナ化(devcontainer)し、環境問題(開発と本番環境の差で生じる問題)と開発構築の手間をなくした
何時でも誰でも、非同期で要件や設計を確認できるようdocs整備を徹底した
CI/CDやIaCをDevOps(自動化)を導入し、運用トラブルを最小限に抑えて気持ちよく開発に専念できる自動化を導入した
これらの対応に加えて、初期にターゲットとしたユーザのデータリテラシーが高かったことも相まって、 新機能を追加しては、更に新しい機能を追加したい要望の好循環が起きて順調に軌道に乗ことができました😃
この時期の取り組みについては、昨年のイベントの登壇資料もご参照ください 🙏 speakerdeck.com
しかし、加速度的なデータ分析基盤の需要の高まりとともに壁にブチ当たる
越える必要がある壁⛰️
多数の関連会社にまたがる複数の部門でデータ分析基盤の需要があり、ドメイン知識をキャッチアップする必要がある💦
全ての部門で日々新しいデータ項目が追加され続けており、継続的な保守運用が必須となる💦
新しい定義が必要な個人・顧客情報保護のための情報統制を組み込んだ開発が必要になる💦
人材確保の面で、最先端の技術を使いこなせるデータエンジニアは非常に少なく人員増強が厳しい💦
つまるところ、数人のデータエンジニアで数百人分のデータ基盤需要を満たさなければならない、ボトルネック問題が深刻な問題として見えて来ました
壁を乗り越えてステップアップする挑戦💪
一つでさえ越えるのが難しいと思える壁が複数立ちはだかる現実が見えてきました💦
これまでに経験してきたバックエンド開発の考え方から、
プラットフォームエンジニアリング、マイクロサービス、DDD...を参考にし、 データ基盤技術ではDatamesh、Scaled Architectureなどをキャッチアップしつつディスカッションを重ねて来ました📚
加えて、弊社の特色として現場部門は技術力があるという利点も加えて、次のステップアップを目指す開発体制として、
並列型への移行を目指すことにしました。
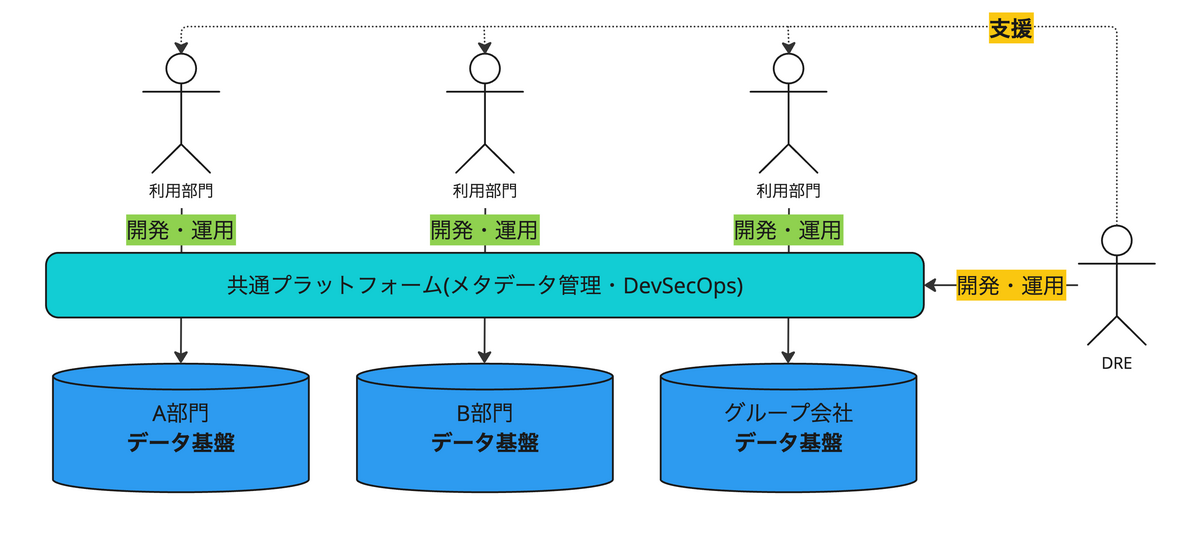
並列型開発体制の利点
データの発生元・利用する現場での開発・運用が可能で、素早く・品質が高いデータ基盤開発ができる
必要なリソースの大部分を現場に委譲できるため、データエンジニアリソースの増強を急ぐ必要がなくなる
総じて、我々データエンジニア(DRE)がボトルネックとなるリスクを小さくできる点にあります😃
反面、しっかり機能させるために整備が必要なこと
サイロ化が起こらないよう、どこにどのようなデータがあるかを中央でしっかり管理する必要がある
各データ基盤間のデータの流通がスムーズに行える仕組みを整える
データエンジニアリングに関する専門知識がなくとも開発を行えるように技術プラットフォームを整備する
データエンジニアリングの知識を広く伝え、浸透するよう支援・普及活動を実施する
開発をそれぞれの現場部門へ委譲できるよう、スタート期で溜めた知見のブラッシュアップと各種の最先端のデータ技術を詰め込んだプラットフォーム開発を急ピッチで進めております💪
データ基盤プラットフォームに必要な技術について🦾
メタデータ管理の仕組みを作る
複数のデータ基盤が立ち上がってくる中でサイロ化を起こさないよう、何がどこにあるかの管理はしっかりする必要があります。 Atlanを試してみようかと思っています🤔
より開発生産性を高める開発フローに進化する
開発効率の影響が、広い範囲に及ぶようになります。トランクベース開発でより柔軟な開発フローしたいと思います。そのためにCI・CDを高いレベルに引き上げる必要性を感じています。
DevSecOps、開発プロセスにセキュリティ実装を組み込む
これからのデータ基盤は、情報保護の対応が必須です。これまでは取り込むデータに対して一つ一つ吟味、ディスカッションを経てマスキング設定を実装してきました。
このプロセスを新開発体制にしっかり組み込み。 さらに複雑化するデータガバナンスの構築にはIMMUTAを試してみようかと思っています🤔
多様で複雑なパイプラインを制御するオーケストレーションを導入する
これまでのパイプラインは単純な定期実行の制御で足りていたためdbtCloudのJobを使っていました。
これからは、S3へのファイルputを起点にしたり、複数の依存関係を制御したりと多様なパイプラインを制御する必要が見込まれます。
Dagsterの導入を決めました。最先端の知見をお持ちの@sista05さんに参画いただいてブーストする見込みです。
cf.先日のsista05さんによるアドベントカレンダー投稿
引き続きコアとなるのはSnowflake
やはり引き続きコアとなるのはSnowflakeです、部門に分散したデータ基盤の運用でサイロ化を防ぐにはSnowflakeの理念の根幹にあるデータを一箇所に閉じ込めない仕組みが必須です。
データをクラウドストレージにロードさえしてしまえば、権限制御(ダイナミックデータマスキング、データシェア...etc)によって、あらゆる場所で取り出してデータを利用可能となります。
そして、取り出す処理もコンテナサービス(SPCS)によってSQLに留まらない、あらゆるアプリケーションの実装が可能となってきました。
引き続き基盤の強力なエンジンとして活用していきます🚀
ステップアップを成し遂げるために
'23年はスタート期の直列型開発体制と新しい並列型体制への移行のための整備を並行で進行してきました。
年末になってようやく形になって来たというところです😃
'24年は新開発体制元年となります。引き続き最先端のデータ技術の取り込みと挑戦を続けていきます💪 (また来年末に成果をまとめて書くかも🤔)