どもー、かとじゅん(@j5ik2o)です。
Scala Advent Calendar 2020 - Qiitaの2日目の記事です。 今回の記事は掲題のとおり、DynamoDBのI/OをAkka Streamsで効率的に実装してみようというネタです。
DynamoDBのAPI操作では以下のような注意点があります。よく知られている制限だと思います。
BatchWriteItemは一度に上限件数25件を超えて書き込めない。書き込めなかったアイテム(unprocessedItems)を再度書き込む必要があるBatchGetItemは一度に上限件数100件を超えて取得できない。読み込めなかったキー(unprocessedKeys)を再度読み込む必要があるQuery/ScanはlastEvaluatedKeyがある場合は再度それを使ってクエリし直す必要がある
こちらの制限をAkka Streamsを使って取っ払ってみたいと思います。取っ払うというか仕様どおり実装するというだけですね。
ちなみに、ここで紹介するコードはGitHub - j5ik2o/akka-stream-dynamodbにあります。
雑にAkka Streams入門
何はともあれ、Akka Streamsに入門。あまり長くなると読むのが大変なので、雑に解説します…。詳しくは公式ドキュメントを読んでください。
Akka StreamsはReactive Streamsに準拠した実装の1つです。終わりのない要素の列としてのストリームのデータをプロデューサ・コンシューマパターンで処理します。データ量が膨大で予測がつかない場合に適しており、データフロー上のバッファがオーバーフローする問題にも対応できます。
以下は1から10までの値を持つコレクションを作って、mapを2回しfoldLeftでVectorに詰め直す処理です。リスト1では、1つ目のmapを全ての要素に適用し終えてから、2つ目のmapを全ての要素に適用します。
リスト1 正格評価型コレクション
val result = (1 to 3) .map { i => print(s"A: $ -> "); i } .map { i => print(s"B: $ -> "); i } .foldLeft(Vector.empty)(_ :+ _) println(result)
リスト1のコンソール出力結果
A: 1 -> A: 2 -> A: 3 -> B: 1 -> B: 2 -> B: 3 -> Vector(1, 2, 3)

Scalaでは.viewを使って遅延評価型コレクションを使うとAとBのmapを交互に実行します。resultは同じ値になります。
リスト2 遅延評価型コレクション
val result = (1 to 3).view // (1 to 3).to(LazyList)としてもよい .map { i => print(s"A: $ -> "); i } .map { i => print(s"B: $ -> "); i } .foldLeft(Vector.empty)(_ :+ _) println(result)
リスト2のコンソール出力結果
A: 1 -> B: 1 -> A: 2 -> B: 2 -> A: 3 -> B: 3 -> Vector(1, 2, 3)

リスト2をAkka Streamsで書き直すとリスト3のとおりになります。Akka Streamsを使うので、書き方が異なりますが同じ結果になります。Source#applyを使ってコレクションの要素を1つずつストリームに流していき、mapを2回行い、最終的にfoldでVectorに詰め直します。ちなみに、Source(1 to 3)とすると要素を下流に一つずつ流しますが、Source.single(1 to 3)とするとコレクションを1要素として下流に流します。
リスト3 Akka Streams
val future = Source(1 to 3) // Source.apply(1 to 3) .map { i => print(s"A: $i -> "); i } .map { i => print(s"B: $i -> "); i } .runWith(Sink.fold(Vector.empty[Int])(_ :+ _)) val result = Await.result(future, Duration.Inf) println(result)
リスト3のコンソール出力結果
A: 1 -> B: 1 -> A: 2 -> B: 2 -> A: 3 -> B: 3 -> Vector(1, 2, 3)
Source/Flow/SinkとRunnableGraph
Sourceはデータを提供する型です。Sinkはデータを消費する型です。ストリームを実行するにはSourceとSinkを結合する必要があります。上記の場合は結合すると戻り値としてFuture[T]が戻ってきます。
もう一つ、SourceやSinkに結合できる、Flowという型があります。これはmapやfilterなどの中間の処理を記述できます。
そして、Source, Flow, Sinkの結合規則は以下のようになります。FlowはSourceに結合するとSourceに、Sinkに結合するとSinkになります。最終的にはSourceとSinkは結合する必要があります。
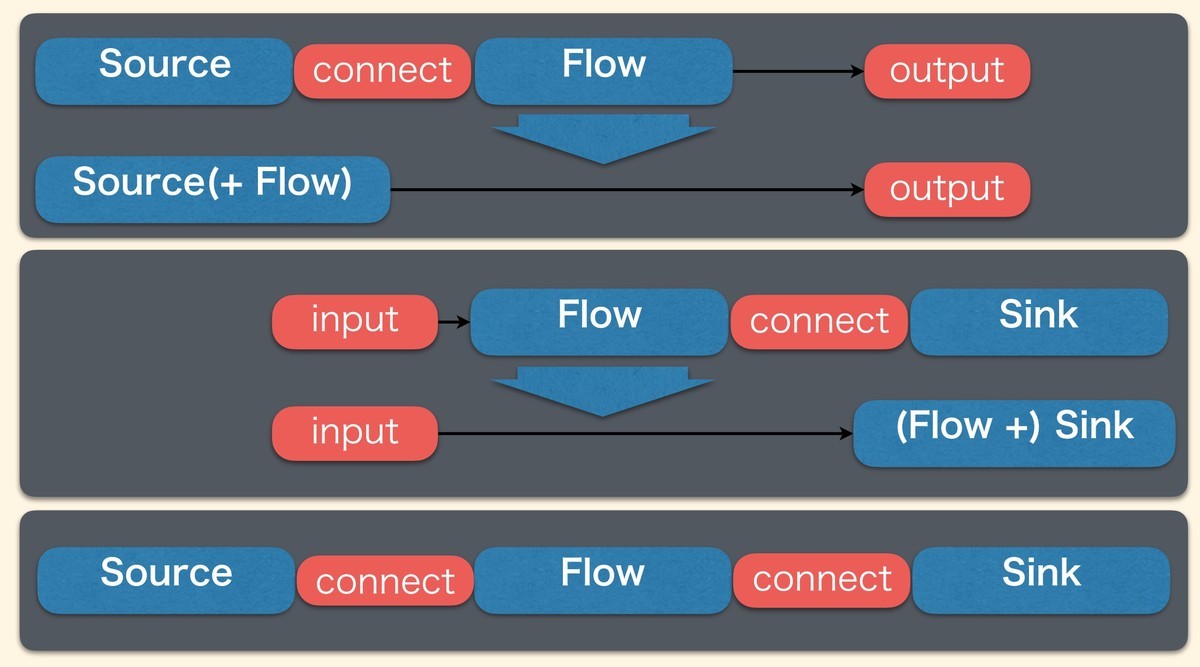
Source#viaを使うとSourceにFlowを結合することができ、Flow#toMatを使うとSinkにFlowを結合できます(NotUsedやKeep.rightは後述します)。
val source: Source[Int, NotUsed] = Source(1 to 10) .via(Flow[Int].map(_ * 2)) val sink: Sink[Int, Future[Seq[Int]]] = Flow[Int].map(_ * 2) .toMat(Sink.seq)(Keep.right) val runnableGraph: RunnableGraph[Future[Seq[Int]]] = Source(1 to 10) .via(Flow[Int].map(_ * 2)) .toMat(Sink.seq)(Keep.right) val future: Future[Seq[Int]] = runnableGraph.run()
これらを結合するとRunnableGraphになります。RunnableGraphを実行するにはrunメソッドを呼び出します。
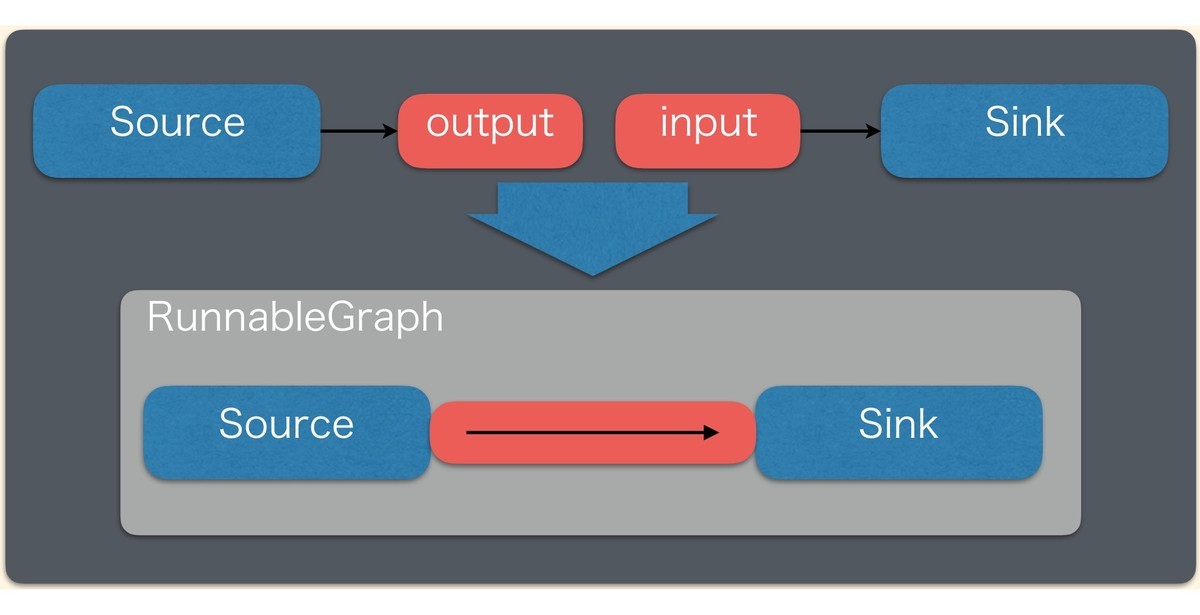
簡単なストリーム処理の例
簡単なストリーム処理の例は以下を参考にしてください。
Source[A, B]やSink[A, B]の型には型パラメータAの要素型以外に、型パラメータBのマテリアライズドバリューという型が存在します。マテリアライズドバリューはストリームに関する補助値という意味になります。この補助値はAPIによって変わります。以下の例ではSource#applyのマテリアライズドバリューはNotUsed(未使用)、Sink#seqではFuture[Seq[Int]]です。toMatメソッドでKeep.rightを指定すると、runメソッドの戻り値としてSink側のマテリアライズドバリューであるFuture[Seq[Int]]が取得できます。
val future = Source(1 to 10) // Source#applyはSource[Int, NotUsed] .via(Flow[Int].map(_ * 2)) .toMat(Sink.seq)(Keep.right) // Sink#seqはSink[Int, Future[Seq[Int]]] .run() val result = Await.result(future, Duration.Inf) println(result)
上記の書き方を簡易的にしたものが以下です。
val future1 = Source(1 to 10) .map(_ * 2) // .via(Flow[Int].map(_ * 2)) と同じ意味 .runWith(Sink.seq) // .toMat(Sink.seq)(Keep.right).run() と同じ意味 val result1 = Await.result(future1, Duration.Inf) println(result1)
AWSクライアントをAkka Streamsに組み込む
前置きが長くなりましたが1、本題に戻りたいところですが… その前にAkka StreamsとAWSクライアントをどのように結合させるかを検討します。そもそも組み込むとか考えずにAlpakkaを使うという手もありますが、今回は具体的にどういう結合方法があるかみていくのであえて使いません。
今回は、AWS SDK v2のDynamoDbAsyncClientをAkka Streamsの実装でラップしたクライアントDynamoDBStreamClientを実装することにします。このDynamoDBStreamClientは内部にDynamoDbAsyncClientを持っている前提にします。
final class DynamoDBStreamClient( client: DynamoDbAsyncClient, // 以下略
PutItemをAkka Streamsから呼び出す
アイテムの書き込みを行うためのDynamoDBStreamClient#putItemFlowメソッドはFlow[PutItemRequest, PutItemResponse, NotUsed]型です。PutItemRequestを受け取るとPutItemResponseを返すためのFlowです。内部の実装では、DynamoDbAsyncClient#putItemを呼び出すだけなのですが、実装方法は以下の3つあります。ここでは便宜上別名を付けることにします。
akka.stream.scaladsl.Flow#mapAsync+scala.jdk.FutureConverters(別名ScalaJDK)akka.stream.scaladsl.Flow#mapAsync+scala.compat.java8.FutureConverters(別名ScalaCompatJava8)akka.stream.javadsl.Flow#mapAsync(別名JavaFlow)
順番に説明します。
1つ目はakka.stream.scaladsl.Flow#mapAsyncを使う方法です。mapAsyncはscala.concurrent.Futureを返す関数をFlowにできるAPIです。DynamoDbAsyncClient#putItemはjava.util.concurrent.CompletableFuture[PutItemResponse]を返すので、そのままではmapAsyncに渡せないので、import scala.jdk.FutureConverters._などとしたうえでclient.putItem(_).asScalaとしてjava.util.concurrent.CompletableFuture[PutItemResponse]をscala.concurrent.Future[PutItemResponse]へ変換できるようにします。(scala.jdk.FutureConvertersはScala2.13.xでなければ使えません)
2つ目はscala.compat.java8.FutureConvertersを使う方法ですが、1つ目と同等の機能です。この機能はscala/scala-java8-compatに含まれる機能です。Scala2.13.xより前のバージョンではこちらを使います。
3つ目はakka.stream.javadsl.Flow#mapAsyncを使う方法です。java.util.concurrent.CompletableFuture[PutItemResponse]をそのまま使うことができます。ただしscaladslのSource,Flow,Sinkなどの部品と結合させる場合はasScalaとして変換が必要になります。
final class DynamoDBStreamClient( client: DynamoDbAsyncClient, putItemFlowMode: FlowMode.Value = FlowMode.Java, getItemFlowMode: FlowMode.Value = FlowMode.Java, deleteItemFlowMode: FlowMode.Value = FlowMode.Java, batchGetItemFlowMode: FlowModeWithPublisher.Value = FlowModeWithPublisher.Java, batchWriteItemFlowMode: FlowMode.Value = FlowMode.Java, queryFlowMode: FlowModeWithPublisher.Value = FlowModeWithPublisher.Java, scanFlowMode: FlowModeWithPublisher.Value = FlowModeWithPublisher.Java ) { // ... def putItemFlow: Flow[PutItemRequest, PutItemResponse, NotUsed] = { putItemFlowMode match { case FlowMode.ScalaJDK => import scala.jdk.FutureConverters._ Flow[PutItemRequest].mapAsync(1)(client.putItem(_).asScala) case FlowMode.ScalaCompatJava8 => import scala.compat.java8.FutureConverters._ Flow[PutItemRequest].mapAsync(1)(client.putItem(_).toScala) case FlowMode.JavaFlow => import akka.stream.javadsl.{Flow => JavaFlow} JavaFlow .create[PutItemRequest]() .mapAsync( 1, new akka.japi.function.Function[PutItemRequest, CompletableFuture[PutItemResponse]] { override def apply(param: PutItemRequest): CompletableFuture[PutItemResponse] = client.putItem(param) } ) .asScala } }
※上記は実験用のコードなので、FlowModeのコンストラクタ引数が複数ありますがこんなに沢山不要です。パフォーマンスがよいもの1つだけでよい気がします。
PutItemベンチマーク
以下がローカルでDynamoDBLocalとJMHを使ったレイテンシのベンチマークです。設定はデフォルトのままです。ベンチマークのコードはこちら。このベンチマークでは本番でテストしているわけでないので、あくまで参考値としてみてください。まぁこの手のレイヤーを挟むとパフォーマンスは悪くなりますが、思ったより劣化してなさそうです。
95%tileは大きな差はないのですがScalaCompatJava8とScalaJDKはMaxが大きくなっています。原因はまだ調査していません…。ばらつきの小さい JavaFlowを使うほうが良さそうです。
| method | n | 95%tile(msec) | max(msec) |
|---|---|---|---|
| ScalaCompatJava8 | 33395 | 6.070 | 169.869 |
| ScalaJDK | 33505 | 6.005 | 611.320 |
| JavaFlow | 33774 | 6.029 | 87.949 |
| DynamoDbAsyncClient#putItem | 34326 | 5.972 | 88.474 |
※別途AWS環境での負荷試験でScalaCompatJava8とJavaFlowと比較すると、ScalaCompatJava8のほうが1~2秒ぐらいレイテンシがスパイクすることがあるようです。原因はよく分かっていない…。
BatchWriteItem API
DynamoDBで一度に複数のアイテムを書き込むBatchWriteItemというAPIには、一度に書き込めるのは25件までという制約があります。複数のテーブルに跨がるリクエストでも要求としては25件までです。
たとえば、50件を書き込むならば、2回に分けて書き込む必要があります。面倒ですね。
どのようにするかというと以下のとおりです。
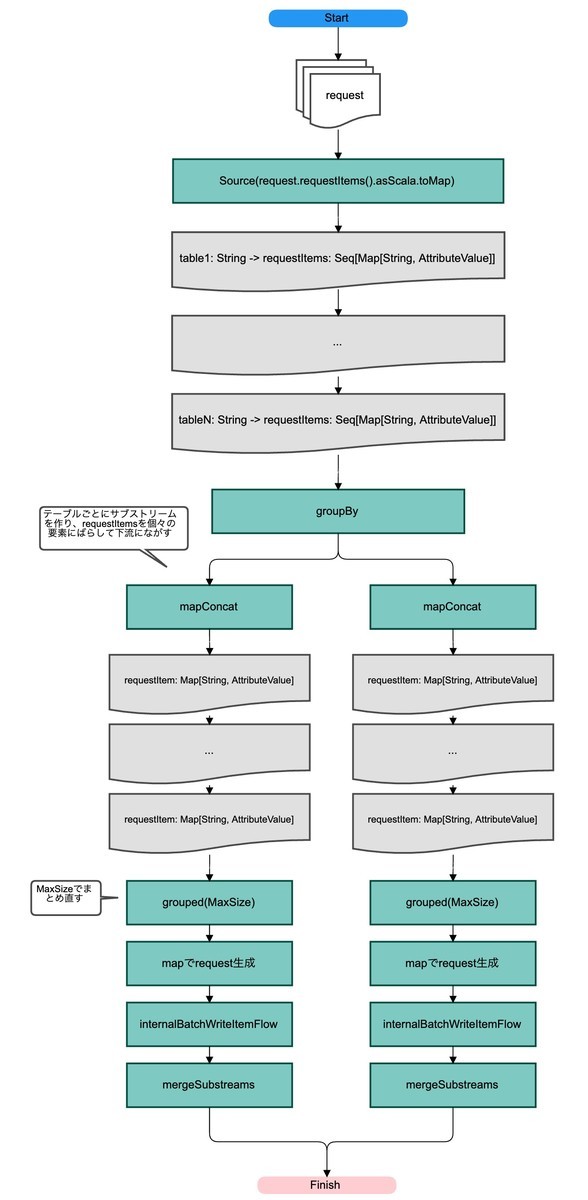
DynamoDbAsyncClient#batchWriteItemをFlowでラップするメソッドinternalBatchWriteItemFlowを定義するBatchWriteItemRequest#requestItemsが25件以上なら、テーブル毎に25件ずつにまとめ直したコレクションをinternalBatchWriteItemFlowにながす
Flow#flatMapConcatは引数にSourceを返す関数を渡すと、FlowにSourceを結合することができます。その関数内でリクエストのアイテムが25件を超えている場合、以下を行います。
BatchWriteItemRequest#requestItemsをScalaのMap型に変換しSource#applyに渡すことでMapのエントリを下流に1個ずつ流しますgroupByを使ってテーブル毎にサブストリームに分割します。shardSizeはサブストリームの数を示しています。デフォルトはInt.MaxValueです- サブストリーム内で
mapConcatを使ってエントリの値であるコレクションを1個ずつ下流に流します(Flow#mapConcatは引数に指定した関数が返すコレクションの要素を1つずつ下流に流します) groupedで上限の25件でまとめ直します。mapの中でその25件を使ってリクエストを作り直し、internalBatchWriteItemFlowに渡します
// DynamoDbAsyncClient#batchWriteItemをFlowでラップするメソッド private def internalBatchWriteItemFlow : Flow[BatchWriteItemRequest, BatchWriteItemResponse, NotUsed] = { batchWriteItemFlowMode match { case FlowMode.ScalaJDK => import scala.jdk.FutureConverters._ Flow[BatchWriteItemRequest].mapAsync(1)(client.batchWriteItem(_).asScala) case FlowMode.ScalaCompatJava8 => import scala.compat.java8.FutureConverters._ Flow[BatchWriteItemRequest].mapAsync(1)(client.batchWriteItem(_).toScala) case FlowMode.Java => JavaFlow .create[BatchWriteItemRequest]() .mapAsync( 1, new function.Function[ BatchWriteItemRequest, CompletableFuture[BatchWriteItemResponse] ] { override def apply( param: BatchWriteItemRequest ): CompletableFuture[BatchWriteItemResponse] = client.batchWriteItem(param) } ) .asScala } } // BatchWriteItemRequest#requestItemsが25件以上なら、テーブル毎に25件ずつにまとめ直して、batchWriteItemを実行します。 private def internalAwareBatchWriteItemFlow( shardSize: Int ): Flow[BatchWriteItemRequest, BatchWriteItemResponse, NotUsed] = { Flow[BatchWriteItemRequest].flatMapConcat { request => if ( request.requestItems().asScala.exists { case (_, items) => items.size > BatchWriteItemMaxSize } ) { Source(request.requestItems().asScala.toMap) .groupBy(shardSize, { case (k, _) => math.abs(k.##) % shardSize }) .mapConcat { case (k, v) => v.asScala.toVector.map((k, _)) } .grouped(BatchWriteItemMaxSize) .map { items => val tableName = items.head._1 val requestItems = items.map(_._2) request.toBuilder.requestItems(Map(tableName -> requestItems.asJava).asJava).build() } .via(internalBatchWriteItemFlow) .mergeSubstreams } else Source.single(request).via(internalBatchWriteItemFlow) } }
処理フローを絵にするとこんな感じです。考え方としてはそれほど難しくなく、アイテムが多いものはばらしてストリームに流し、下流で上限サイズでまとめ直しBatchWriteItemを行うだけです。
書き込めなかった未処理のアイテム(unprocessedItems)を再度書き込む
次に書き込めなかった未処理のアイテム unprocessedItemsのための処理方法を示します。前節で実装したinternalAwareBatchWriteItemFlowからレスポンスが返ってくるので、unprocessedItemsが1件以上であればもう一度リクエストを送る必要があります。以下のようになります。あらかじめリクエスト送信ロジックをメソッド内にloop関数として定義しておき、unprocessedItemsが1件以上あるときに再帰し、accに処理したレスポンスを結合していきます。unprocessedItemsがなくなればaccと最後のレスポンスを返します。
def batchWriteItemFlow( shardSize: Int = Int.MaxValue ): Flow[BatchWriteItemRequest, BatchWriteItemResponse, NotUsed] = { def loop( acc: Source[BatchWriteItemResponse, NotUsed] ): Flow[BatchWriteItemRequest, BatchWriteItemResponse, NotUsed] = Flow[BatchWriteItemRequest].flatMapConcat { request => Source.single(request).via(internalAwareBatchWriteItemFlow(shardSize)).flatMapConcat { response => val unprocessedItems = Option( response .unprocessedItems() ).map(_.asScala.toMap) .map(_.map { case (k, v) => (k, v.asScala.toVector) }) .getOrElse(Map.empty) if (response.hasUnprocessedItems && unprocessedItems.nonEmpty) { val nextRequest = request.toBuilder .requestItems(unprocessedItems.map { case (k, v) => (k, v.asJava) }.asJava) .build() Source .single(nextRequest) .via(loop(Source.combine(acc, Source.single(response))(Concat(_)))) } else Source.combine(acc, Source.single(response))(Concat(_)) } } loop(Source.empty) }
BatchWriteItemのベンチマーク
レイテンシのベンチマークは以下です。unprocessedItemsはローカル環境では発生しませんでしたので、単純に書き込み処理だけの計測になります。一度に書き込む件数は125件です。JavaFlowはレイテンシのばらつきが少なく安定しています。
| method | n | 95%tile(msec) | max(msec) |
|---|---|---|---|
| ScalaCompatJava8 | 712 | 251.855 | 593.494 |
| ScalaJDK | 733 | 232.338 | 353.894 |
| JavaFlow | 724 | 239.272 | 340.787 |
| DynamoDbAsyncClient#batchWriteItem | 786 | 240.897 | 385.100 |
BatchGetItem API
BatchGetItemにも最大100件までという制限があります。これもBatchWriteItemと同じような考え方で、テーブル毎にサブストリームを作り要求されたキーを上限の100件ずつに分けてリクエストするだけです。実際のコードもほとんど同じになります。
private def internalAwareBatchGetItemFlow( shardSize: Int ): Flow[BatchGetItemRequest, BatchGetItemResponse, NotUsed] = Flow[BatchGetItemRequest].flatMapConcat { request => if ( request.requestItems().asScala.exists { case (_, items) => items.keys().size > BatchGetItemMaxSize } ) { Source(request.requestItems().asScala.toMap) .groupBy(shardSize, { case (k, _) => math.abs(k.##) % shardSize }) .mapConcat { case (k, v) => v.keys.asScala.toVector.map((k, _)) } .grouped(BatchGetItemMaxSize) .map { items => val tableName = items.head._1 val keys = items.map(_._2) val params = KeysAndAttributes.builder().keys(keys.asJava).build() request.toBuilder.requestItems(Map(tableName -> params).asJava).build() } .via(internalBatchGetItemFlow) .mergeSubstreams } else Source.single(request).via(internalBatchGetItemFlow) }
ここでは具体的に解説しませんが、BatchGetItemの未処理のキーに対してもunprocessedItemsと同じ考え方で再帰的に処理します。
BatchGetItemのベンチマーク
BatchGetItemのベンチマークです。一度に読み込む件数は500件です。このAPIでもJavaFlowがよさそうです。
| method | n | 95%tile(msec) | max(msec) |
|---|---|---|---|
| ScalaCompatJava8 | 2080 | 82.569 | 140.509 |
| ScalaJDK | 2100 | 78.375 | 213.123 |
| JavaFlow | 2084 | 79.299 | 110.232 |
| Publisher | 2127 | 85.422 | 129.630 |
| DynamoDbAsyncClient#batchGetItem | 3605 | 54.900 | 78.381 |
※PublisherというのはDynamoDbAsyncClient#batchGetItemPaginatorというreactive streamsのPublisher型を利用した場合の計測値です。
Query/Scan API
Query/Scanでは、1度のリクエストで取得できるデータの最大容量の上限が決まっています。大きなデータを取得する際は、レスポンスに含まれるlastEvaluatedKeyをリクエストのexclusiveStartKeyに設定してリクエストして、残りのデータを取得する必要があります。
以下はQueryの場合の例です。Scanの場合もほとんど同じになります。詳しくはこちらを参照してください。
def querySource( queryRequest: QueryRequest, maxOpt: Option[Long] ): Source[QueryResponse, NotUsed] = { def loop( queryRequest: QueryRequest, maxOpt: Option[Long], lastEvaluatedKey: Option[Map[String, AttributeValue]] = None, acc: Source[QueryResponse, NotUsed] = Source.empty, count: Long = 0 ): Source[QueryResponse, NotUsed] = { val newQueryRequest = lastEvaluatedKey match { case None => queryRequest case Some(_) => queryRequest.toBuilder.exclusiveStartKey(lastEvaluatedKey.map(_.asJava).orNull).build() } Source .single(newQueryRequest) .via(internalQueryFlow) .flatMapConcat { response => val lastEvaluatedKey = Option(response.lastEvaluatedKey).map(_.asScala.toMap).getOrElse(Map.empty) val combinedSource = Source.combine(acc, Source.single(response))(Concat(_)) if ( response.hasLastEvaluatedKey && response.lastEvaluatedKey().size() > 0 && maxOpt.fold(true) { max => (count + response.count()) < max } ) { loop( queryRequest, maxOpt, Some(lastEvaluatedKey), combinedSource, count + response.count() ) } else combinedSource } } loop(queryRequest, maxOpt) }
※Query/Scanのベンチマークの結果は時間がなくて取れませんでした…。
まとめ
ということで、API仕様上の制限を取り払って便利に使える実装を書いてみました。まぁ実現方法はscala.concurrent.Futureなどでもいいのですが、Akka Streamsを学ぶネタとしてはこの手の単純なI/O系の処理がお手軽でいいのでは?ということで記事にしてみました。参考になれば幸いです。
-
雑な入門解説になっているので、本家のドキュメントを読むことをお勧めします。↩