みなさん、こんにちは!Chatworkの原田 (@shinharad) です。
今回は、私が最近取り組んでいる、既存のScalaアプリケーションからAkkaの依存を切り離す準備を進めている話を書こうと思います。Akkaの切り離し方は色々あると思いますが、一つの方法として参考にしていただければと思います。
なお、現時点ではAkkaを切り離すことでコスト面での効果が最も大きいアプリケーションを対象として進めています。今後他のアプリケーションも同様にAkkaを切り離すかどうかは、状況を見ながら判断していくことになりそうです。
Akkaを切り離すに至った背景
Akkaは、並行・分散システムの構築をサポートするツールキットで、弊社ではこれまで多くのScalaアプリケーションで採用してきました。Akkaのエコシステムは包括的かつ強力で、Web APIやストリーム処理、分散処理など、アプリケーションの特性に合わせて幅広く適用できるのが魅力です。
さて、そんなAkkaを既存のアプリケーションから切り離すことにした背景は、以下の記事でも触れていますが、Akkaのライセンス変更が発端となっています。
Akkaの開発元であるLightbend社が、2022年9月にAkka v2.7以降のライセンスを変更し、本番環境でAkkaを利用する場合は、同社の商用ライセンスの契約が必要になりました。
Why We Are Changing the License for Akka | Lightbend
適用されるライセンス料を確認すると、例えば Akka Standard を選択した場合は、コア単位 *1 に$1,995 USDのライセンス料を支払う必要があります。つまり、アプリケーションをスケールさせればさせるほどライセンス料が高くなるという料金設定になっています。
Akka - Build Reactive Microservices | Lightbend
弊社のScalaアプリケーションの中で、比較的多くのコアを割り当てている、ある単一のアプリケーションで試算してみたところ、今後もしもAkka v2.7へバージョンアップした場合は年間のライセンス料として日本円に換算して数千万円以上を支払う必要があることが分かりました。これは今後、ユーザ数の増加に応じてアプリケーションをスケールさせたり、もしも円安が今以上に進行したりすると、ライセンス料は更に高くなる可能性があります。
このアプリケーションは、Akka HTTPを使用したWeb APIであり、Akka ClusterやAkka Persistenceなど、Akkaを使用しなければ実現できないような機能は実装していません。しかし、それにもかかわらず高額なライセンス料が発生してしまうのは、避けたいところです。
そこで、Akkaから他のライブラリへ移行することにしました。
移行先のライブラリ
SoftwareMill社が開発しているtapirを移行先のライブラリとして選定しました。他のライブラリも検討しましたが、開発が活発であることや保守運用性、移行のしやすさを考慮すると、tapirが現時点で最善の選択だろうという判断です。
tapirは、エンドポイントの宣言部分とビジネスロジックを分離して実装できるのが特徴です。以下は公式サイトのサンプルコードより抜粋。
import sttp.tapir._ import sttp.tapir.server.ServerEndpoint import scala.concurrent.Future // エンドポイントの宣言 // `GET /hello?name=xxx` を表している val helloEndpoint: PublicEndpoint[String, Unit, String, Any] = endpoint.get.in("hello").in(query[String]("name")).out(stringBody) // エンドポイントの宣言とビジネスロジックを関連付ける val helloServerEndpoint: ServerEndpoint[Any, Future] = helloEndpoint.serverLogicSuccess(name => Future.successful(s"Hello $name"))
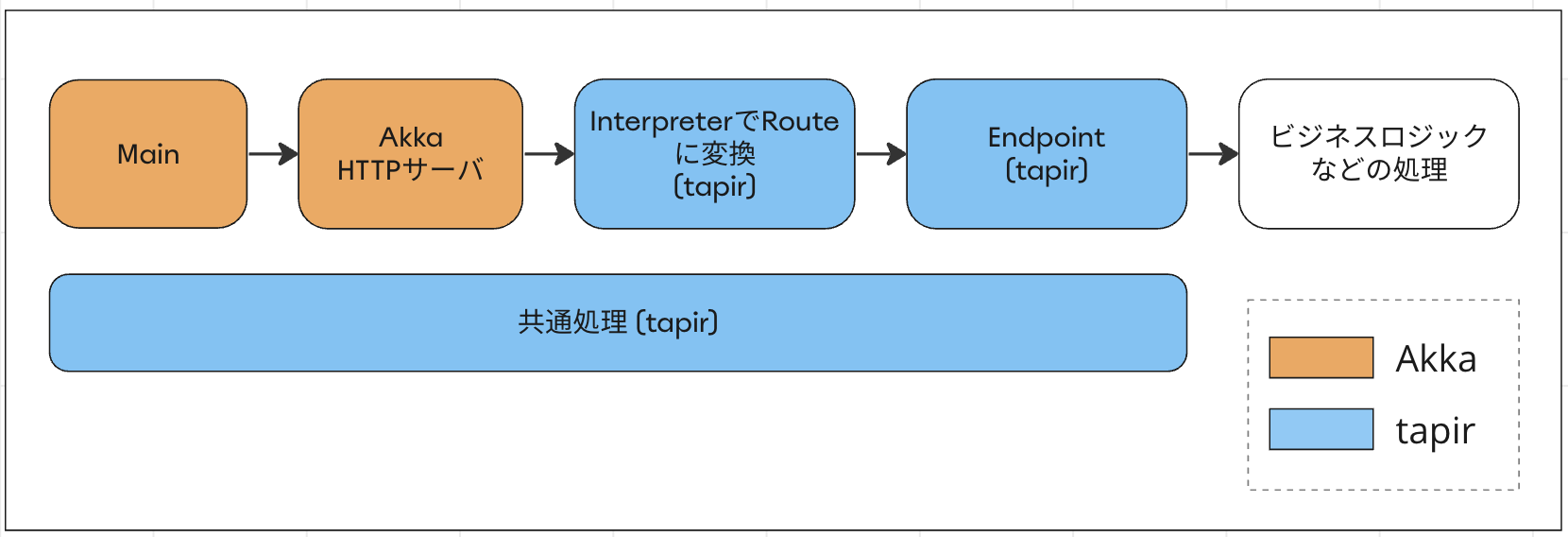
また、tapirはAkka HTTPやNetty、http4sなど、様々なHTTPサーバ用のライブラリと組み合わせて使用することができます。先ほどのサンプルコードで、エンドポイントの宣言部分とビジネスロジックを関連付けている ServerEndpoint は、最終的に各ライブラリ毎に提供されている Interpreter に渡すことで、HTTPサーバの実行に必要なオブジェクトに変換されます。
例えばAkka HTTPの場合は、AkkaHttpServerInterpreter に渡すと akka.http.scaladsl.server.Route に、Nettyの場合は、NettyFutureServerInterpreterに渡すとtapirのNettyServerの実行に必要なsttp.tapir.server.netty.FutureRouteに変換されるといった具合です。
// Akka HTTPの場合 import sttp.tapir.server.akkahttp.AkkaHttpServerInterpreter val route: akka.http.scaladsl.server.Route = AkkaHttpServerInterpreter().toRoute(helloServerEndpoint) // Nettyの場合 import sttp.tapir.server.netty.NettyFutureServerInterpreter val route: sttp.tapir.server.netty.FutureRoute = NettyFutureServerInterpreter().toRoute(helloServerEndpoint)
ここでポイントとなるのが、tapirで実装したエンドポイントは、HTTPサーバ用のライブラリの直接的な依存から切り離された状態にできるということです。
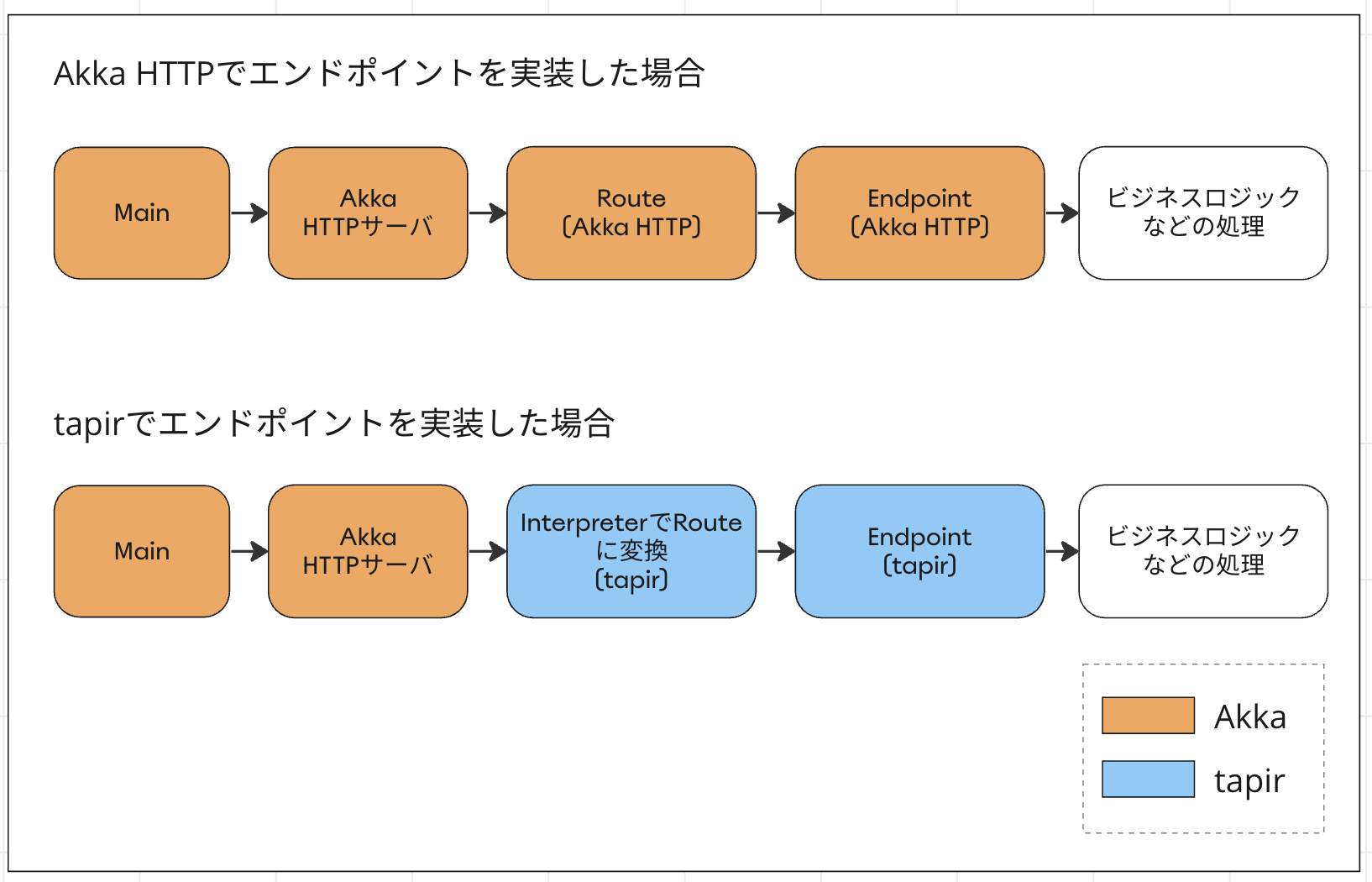
また、Akka HTTPの場合にAkkaHttpServerInterpreterが返すのは、tapirのオブジェクトではなく、純粋なAkka HTTPのakka.http.scaladsl.server.Routeです。そのためRouteを合成することで、移行期間中に移行前後のエンドポイントを並行運用することも可能になります。
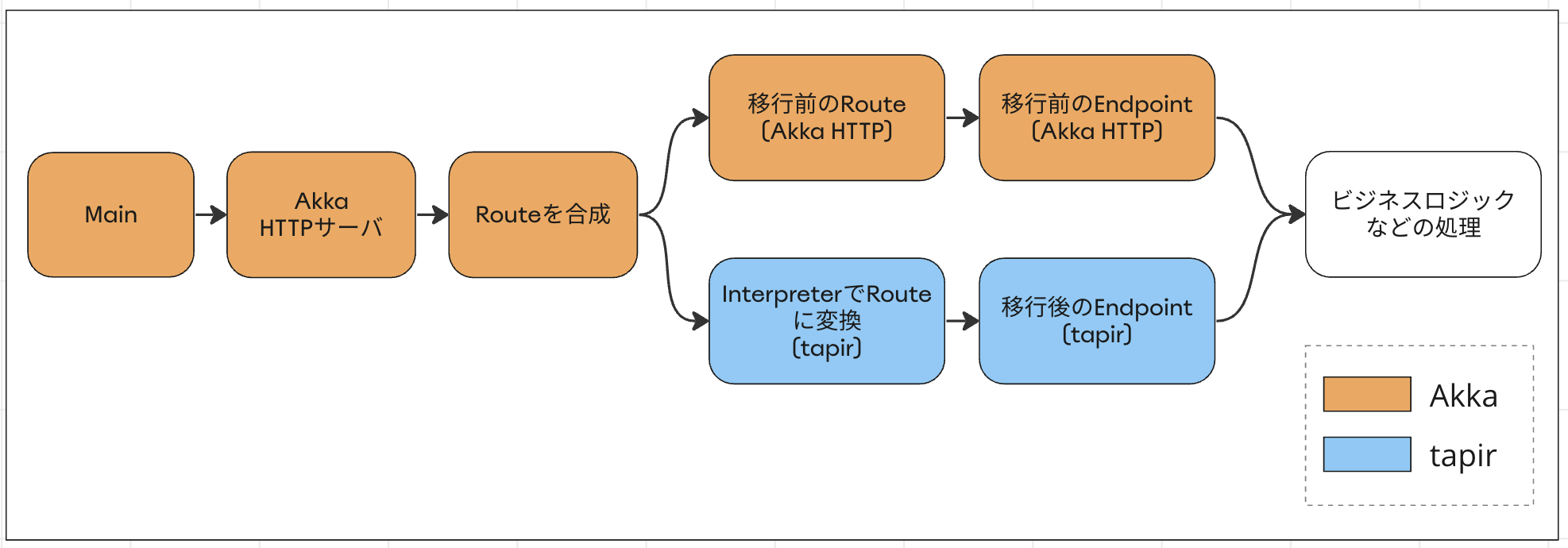
詳細は後述しますが、これらの特性が、本番環境への影響を最小限にしつつ、Akkaを段階的に切り離すのに大きなアドバンテージになると判断しました。
ちなみにSoftwareMill社のブログでもAkkaからtapirへの移行について紹介されています。
Migrating from Akka HTTP to tapir
移行は段階的に実施
tapirを使用したAkkaの切り離しは、本番環境への影響を最小限にするために、下記の通り段階的に実施しました。
- tapir方式での共通処理の開発
- tapir × Akka HTTP構成への移行 (エンドポイント単位に実施)
- tapir × その他のライブラリへの移行 (ここでAkkaを完全に切り離す)
後述しますが、現時点では2の「tapir × Akka HTTP構成への移行」を終えたところで一旦移行作業は止めています。3の「tapir × その他のライブラリへの移行」は、OSSの状況を見て環境が整ったら着手する予定です。
それでは、各ステップの詳細について順を追って説明します。
1. tapir方式での共通処理の開発
まずはtapir方式の基礎部分の開発です。これまでAkka HTTPの提供機能を使用して実現していたValidationやエラーハンドリング、メトリクス、ロギングなどの共通処理を、tapirの提供機能を使用して同等の処理を実装します。
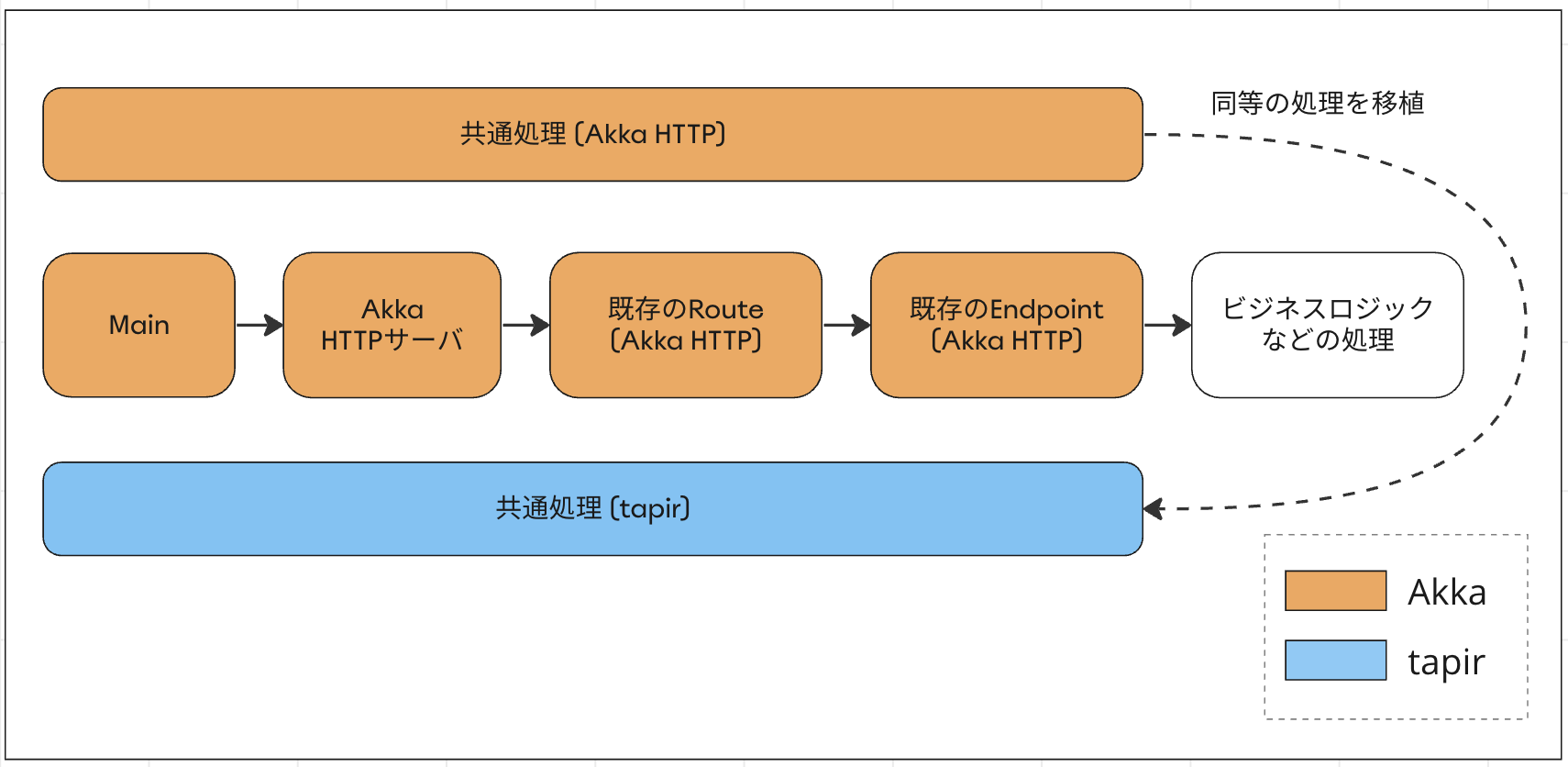
そして、以下はそれぞれの共通処理を実装するにあたって、tapirのどの提供機能で置き換えられるのかをまとめた表になります。
| 共通処理 | Akka HTTP | tapir |
|---|---|---|
| RejectionHandler (Validation) | Directive、RejectionHandler | Codec、DecodeFailureHandler *2 *3 |
| RejectionHandler (Validation以外) | RejectionHandler | Error outputs *4 |
| ExceptionHandler | ExceptionHandler | ExceptionHandler *5 |
| Metrics | Directive | MetricsRequestInterceptor *6 |
| Logging | Directiveなど | MetricsRequestInterceptorなど |
こうして見ると、Akka HTTPの Directive は適用範囲が広いですね。
tapirの提供機能で共通処理を実装する場合、基本的にはInterceptor *7 の仕組みを使用して実装します。ただこれはケースバイケースかなと思っていて、例えば上記の「RejectionHandler (Validation以外)」の場合は、既存の処理をInterceptorで置き換えようとするとどうしても全体の構成が分かりづらくなってしまうため、代替手段としてエンドポイントのエラーをもとに共通メソッドでレスポンスを生成するという工夫をしました。
このステップは苦労したことが多くて、「Akka HTTPで実現していたことを置き換える」という文脈においては、tapirの公式ドキュメントだけでは情報が足りず、tapirの内部実装を確認し、そこから実現性を導き出すということをやっていました。細かいTipsについては今後機会があったらご紹介したいと思います。
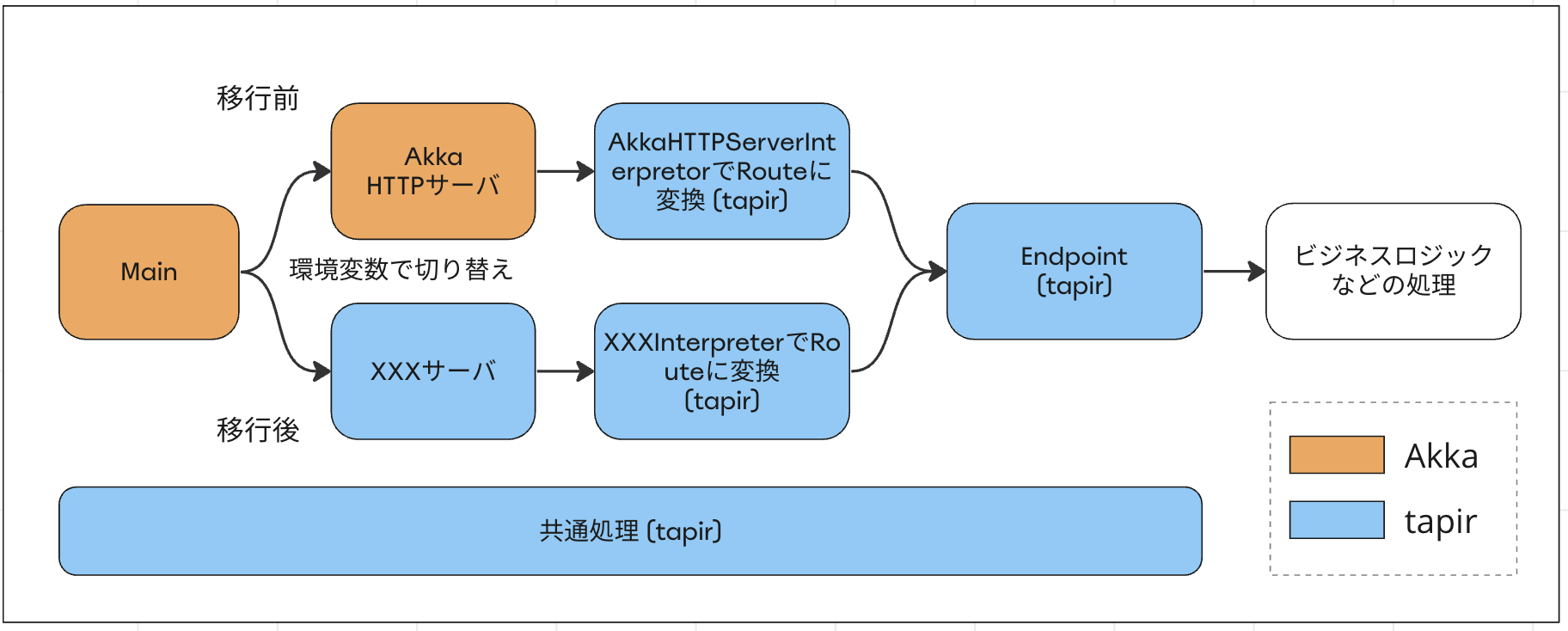
2. tapir × Akka HTTP構成への移行
前のステップでtapir方式の基礎固めをしたので、ここからはAkka HTTPで実装していた既存のエンドポイントを一つずつtapir × Akka HTTP構成に移行していきます。
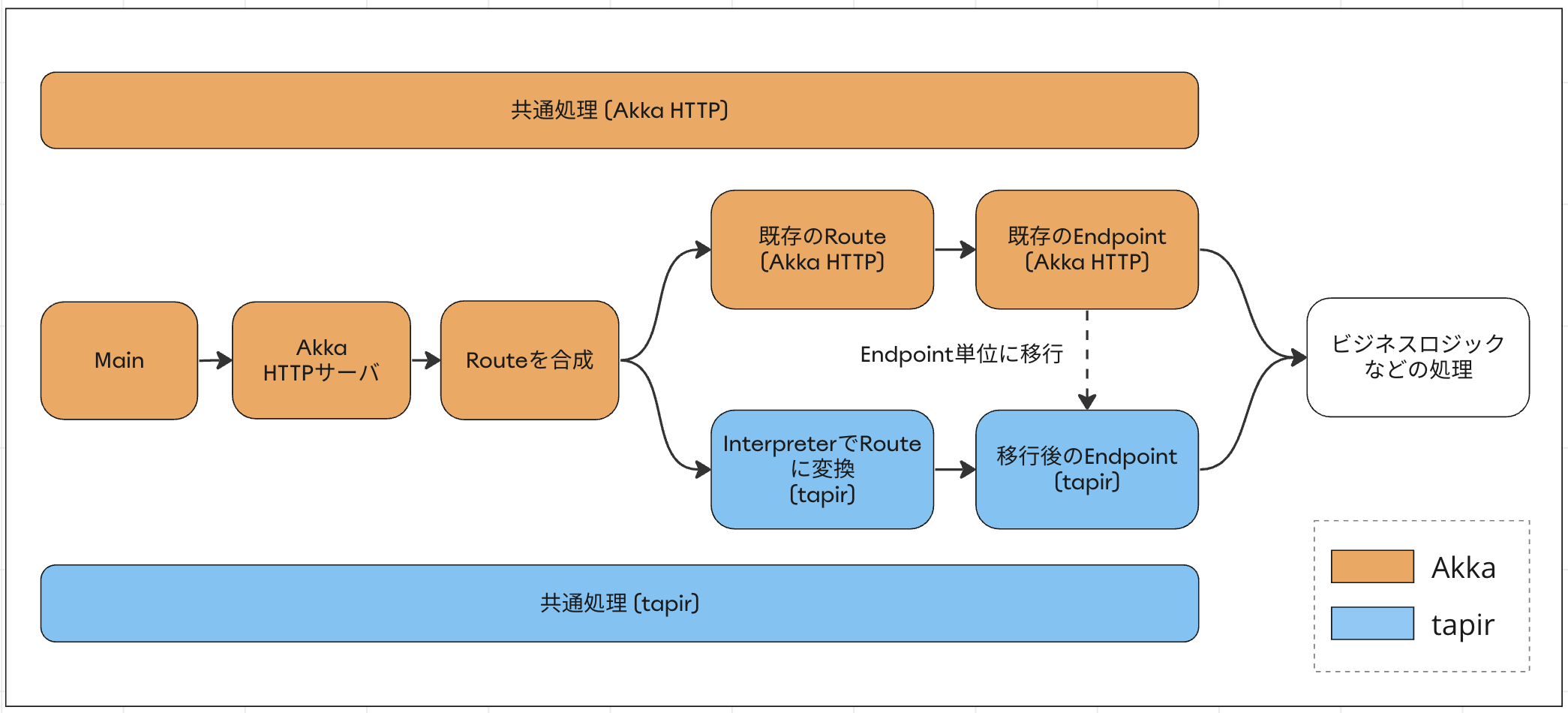
前述の通り、AkkaHttpServerInterpreterで生成した移行後のRouteは、既存のRouteと合成ができます。その際、移行後のRouteを先に記述しておくことで、移行後のエンドポイントが優先的に呼び出されるようになります。これを利用して、移行を終えたエンドポイントは順次リリースしていきます。
// tapir移行前のRoute val routeBefore: Route = ??? // tapir移行後のRoute val routeAfter: Route = AkkaHttpServerInterpreter().toRoute(endpoints) // Routeを合成する (移行後のRouteの優先順位を上げるために先に記述する) val route: Route = routeAfter ~ routeBefore // Akka HTTPサーバを起動する val bindingFuture: Future[Http.ServerBinding] = Http() .newServerAt(host, port) .bindFlow(route)
ここから更に、環境変数でいつでも移行前の状態に戻せるように以下のように改良しました。
// tapir移行前のRoute val routeBefore: Route = ??? val route: Route = if (useTapir) { // 環境変数で切り替えられるようにする // tapir移行後のRoute val routeAfter: Route = AkkaHttpServerInterpreter().toRoute(endpoints) // Routeを合成する (移行後のRouteの優先順位を上げるために先に記述する) routeAfter ~ routeBefore } else { // tapir移行前の状態で起動する routeBefore } // Akka HTTPサーバを起動する val bindingFuture: Future[Http.ServerBinding] = Http() .newServerAt(host, port) .bindFlow(route)
移行期間中はこの仕組みを利用して、移行後の挙動が移行前と同一であることを担保するためのツールを作り、CIで毎回チェックするようにしていました。
このステップでの移行をすべて終えて、移行前の不要になったコードをすべて削除すると、Akka HTTPに直接依存していたエンドポイントはすべて無くなり、tapir経由で間接的にAkka HTTPに依存している、という状態になります。
ちなみに、tapir × Akka HTTP構成へと移行したことで性能面での変化はどうだったかというと、マイナーGCカウントが2割ほど増加したものの、CPU使用率やレスポンスタイムには大きな影響はありませんでした。マイナーGCカウントが増えたのは、ValidationにtapirのCodecを使用したことで、短命なオブジェクトが移行前よりも多く生成されるようになり、GCで回収されるサイクルが短くなったのが要因と考えています。
3. tapir × その他のライブラリへの移行
最後のステップです。いよいよAkkaの依存を完全に切り離します。
まず、Interpreterを使用して、Akkaを切り離した状態での構成でアプリケーションを起動できるようにします。これを移行後として、移行前と移行後のどちらの構成で起動するのかを環境変数で切り替えられるようにしておきます。
本番環境での移行作業は、移行前後のアプリケーションを両方デプロイしておいて、ALBの加重ターゲットグループ *8 やArgo Rollouts *9 などを使用して、トラフィックを徐々に移行後へ流していく方法が安全かなと思います。
ここまでが、移行の全体の流れになります。
前述の通り、このステップは現時点では一旦様子見としています。というのは、当初この移行作業を開始した数ヶ月前は、AkkaをフォークしたPekkoの開発がまだ始まったばかりで、移行先の候補としては挙げづらい状況でした。
そのときは、移行するならtapir × Netty構成だろうなと考えていました。tapirのNettyモジュールは、2023/07現在でまだ安定版はリリースされておらず、機能面ではまだまだ不十分です。ただ、tapirの実装を確認すると、比較的薄く実装されているので、安定版がリリースされるまでの間は、部分的に自前で実装しても運用上そこまで負担にはならないだろうと考えていました。
しかしあれから数ヶ月経過し、つい先日Pekko v1.0.0の正式リリースがアナウンスされました!
Apache Pekko 1.0.0 has been released, see https://t.co/MSxDP1vizP and https://t.co/7dGkbBwBof for more details.
— ApachePekko (@ApachePekko) 2023年7月13日
Its been a long road, many thanks to everyone who participated in this!
PekkoのサポートについてtapirやKamon *10 を確認すると、Pull Requestは作られているので今後サポートされる可能性はありそうです。こうなると、tapir × Pekko HTTP構成も選択肢の1つになってきたかなと感じています。
Add Pekko support by benjamingeer · Pull Request #2883 · softwaremill/tapir · GitHub
Add kamon-pekko and kamon-pekko-http by DieBauer · Pull Request #1264 · kamon-io/Kamon · GitHub
そこで、Pekko周辺の動向を見守るためにこのステップは一旦止めて、しばらくは様子を見ることにしました。
おわりに
tapirへ移行することの最大のメリットは、刻々と変化するOSSの状況に対して、代替ライブラリへの切り替えが比較的容易にできることかなと思っています。移行自体はちょっと大変ですが、この構成にしておくことで、例えばPekkoにしたけど後から別のライブラリに切り替えたい場合でもスムーズに対応できそうです。
Akkaの切り離し方法について検討されている方に今回の記事が参考になれば幸いです。
*1:Core is defined as a hardware core / vCore / vCPU https://www.lightbend.com/akka#pricing
*2:https://tapir.softwaremill.com/en/latest/endpoint/codecs.html
*3:https://tapir.softwaremill.com/en/latest/server/errors.html
*4:https://tapir.softwaremill.com/en/latest/server/errors.html#error-outputs
*5:https://tapir.softwaremill.com/en/latest/server/interceptors.html
*6:https://tapir.softwaremill.com/en/latest/server/observability.html
*7:https://tapir.softwaremill.com/en/latest/server/interceptors.html
*8:https://aws.amazon.com/jp/blogs/aws/new-application-load-balancer-simplifies-deployment-with-weighted-target-groups/
*9:https://argo-rollouts.readthedocs.io/en/stable/
*10:https://kamon.io/docs/latest/guides/installation/plain-application/