サーバーサイド開発部で Scala アプリケーションの開発運用をおこなっている hayasshi (@hayasshi_) です。
昨年 2022 年 10 月 6 日に、Chatwork ではフリープランの制限の変更をおこないました。*1*2
「参加できるグループチャットの累計数」から、「閲覧できるメッセージの期間と数」へと制限が変更になったのですが、 この 閲覧できるメッセージの数 の計算を、Scala のバッチアプリケーションでおこなっています。
今回はそのアプリケーションについて、設計や構成をご紹介したいと思います。
Chatwork フリープランにおけるメッセージ閲覧制限について
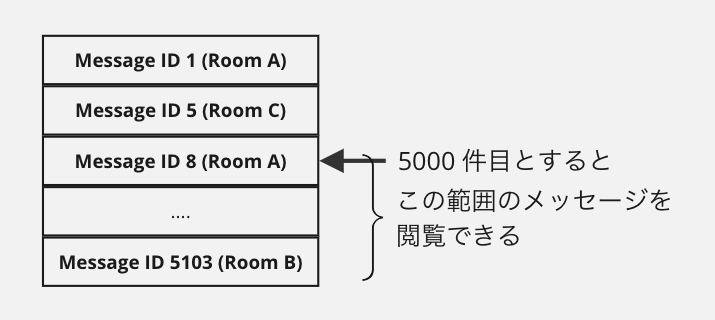
2023 年 4 月 14 日現在、Chatwork フリープランのアカウントが閲覧できるメッセージは、
投稿されてから 40 日以内でかつ、組織全体で 5000 件まで となっています。
「投稿されてから 40 日以内」はメッセージの投稿日時からリアルタイムに計算可能ですが、 「組織全体で 5000 件まで」という制限がやっかいです。
Chatwork では、メッセージの投稿はもちろん、すでにメッセージのやりとりがあるグループチャットに参加したり、退席したりと、アカウントが閲覧できるメッセージはリアルタイムに変動する可能性があります。
新規のメッセージ投稿だけであれば、そのイベントを監視してリアルタイムに数の計算ができるのですが、先に記載したグループチャットへの参加や退席に伴い、アカウントが所属する組織の単位で閲覧できるメッセージの数をリアルタイムに更新していくことは負荷が高いと判断し、日次でのバッチ処理で計算するようにしました。
バッチの構成
メッセージの閲覧制限情報の計算では、Chatwork とフリープランで契約いただいている組織単位で、閲覧可能なメッセージを算出する必要があります。 そのデータを計算するために、大きく 3 つの処理要素に分解しました。
- batch1: フリープランの組織を抽出する処理
- batch2: 対象組織のアカウントと、それらが参加するチャットルームを抽出する処理
- batch3: チャットルームのメッセージを取得し、その組織のメッセージ閲覧制限情報を計算する処理
バッチの構成は下記のようなイメージになります。
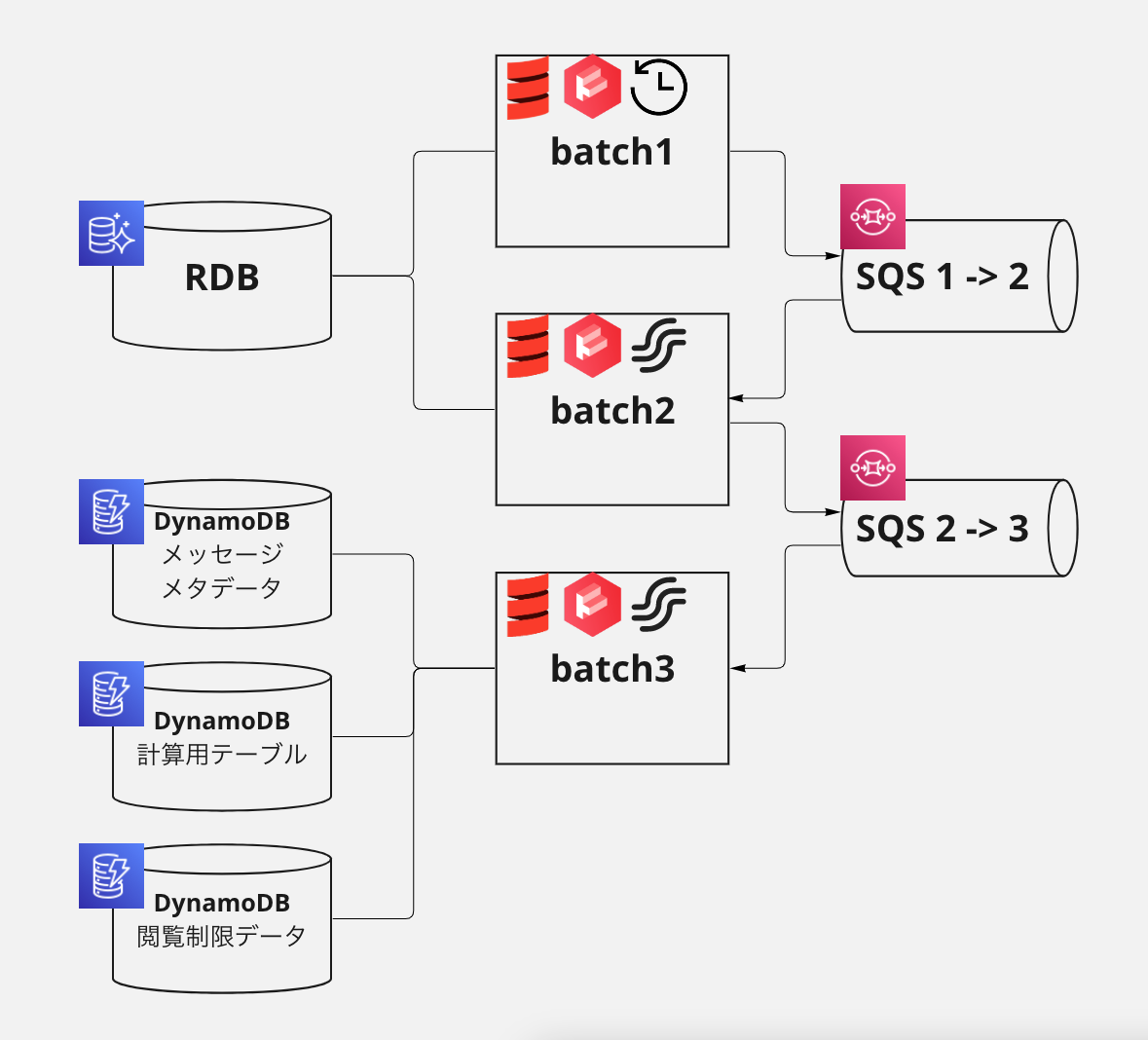
batch1 は、Kubernetes CronJob として定義した、定時実行されるバッチアプリケーションです。 batch2, 3 は、それぞれ前段の処理のアウトプットとなる SQS メッセージを Receive して処理をする、ストリームアプリケーションとしました。
これにより、多くの計算を組織単位で並列におこなうことができ、また一部の処理でエラーが発生した際も、リトライをおこないやすくしています。
計算の中心となるのは batch3 でつかっている計算用の DynamoDB テーブルです。DynamoDB がパーティション単位でソートキー順にソートしてデータを管理する特性と、 Chatwork のメッセージ ID フォーマットが Snowflake 形式で投稿時系列順にソートできる特性をあわせると、DynamoDB にメッセージを Put することで自動的に投稿順にソートされます。その組織が閲覧できるメッセージの一覧がテーブルに入った状態で、新しいメッセージ(ID 降順)から探索することで、最新の 5000 件のメッセージを特定しています。
このような構成とした背景として、Chatwork では Terraform + Atlantis での、AWS リソース定義、review & apply フローが、SRE チームによって整備されています。 これにより、アプリケーションエンジニアが AWS リソースについても、自分たちで構築運用していく土壌が整っています。
当初このバッチについても、Apache Spark などの分散処理フレームワークをつかった設計にしようかと考えましたが、Amazon EMR をつかうにしても、Spark 実行基盤の運用等が負荷になると考え、できるだけフルマネージドなサービスで分散処理できるような構成にしたいと考えました。
結果、リリース後もアプリケーションのメンテナンス以外は特に発生しておらず、利用ミドルウェアについて運用負荷が低い状態を維持できています。
アプリケーションの構成
これらのアプリケーションは、Scala と cats-effect, fs2 をメインライブラリとし、DB アクセスライブラリとして doobie を用いて構築しています。 こちらの記事でチャレンジして得た実績、経験をそのまま利用し、さらにいろいろなユースケースでの利用経験を積めると考えたためです。
実際に batch1 も含め、量の多いデータをメモリを逼迫しない形で取得することとその計算周りは fs2.Stream と相性が良く、処理の制御や並行化を容易におこなうことができました。
私は先の記事のアプリケーションの開発には携わっておらず、今回 cats-effect + fs2 をつかって初めて開発をおこなったのですが、実装で詰まることは少なかったです。
とはいうものの、fs2.Stream の組み立て方を誤って想定していた並行処理にならなくなっていたところを、先の記事を書いたメンバーに調整してもらって爆速にしてもらったり、局所的にしかつかわない代数的データ型で処理の制御をおこなっていた部分を、昨年の新卒メンバーに cats の ContT[IO, A, B] で書き直してもらって可読性を改善してもらったり、関数型に慣れ親しんでいるメンバーにたくさんヘルプももらっています。(ありがたや)
また、この開発で知ったのですが、aws-sdk-java-v2 の DynamoDB Query API に Reactive Streams の org.reactivestreams.Publisher を返すものがあり、fs2-reactive-streams のコネクタをつかって DynamoDB のページネーションを含めた Item の取得を容易に fs2.Stream に取り込めたのが、非常に便利でした。
リリースと課題
そんなこんなでリリースはおこなわれました。リリースにあたっては特に問題はありませんでした。
しかし、開発中におこなったシステムパフォーマンス検証の際にあがった問題として、先のバッチ構成にある計算用の中間テーブルへの書き込み量が多く、ホットパーティションによるスロットル問題と、コストに関する問題の、2つがあがっていました。
ホットパーティションによるスロットル
DynamoDB は、テーブルに対するキャパシティが十分でも、少数のパーティション(例えば同一パーティションキーのみなど)をターゲットとしてリクエストが頻繁(ホット)におこなわれると、パーティション単位での制限にかかり、スロットルが引き起こされることがあります。*3
今回の計算用テーブルでは、組織 ID をパーティションキーに、メッセージ ID をソートキーとして、組織単位の処理で書き込みをおこない、ソートをおこなっています。 この書き込みの際にパーティション制限にかかりやすい設計となってしまいました。
この制限によるスロットル期間がそこまで長くないため、AWS SDK のバックオフ付きリトライの範囲内で処理することができていましたが、リトライを伴いながら処理をおこなうため、全体の処理時間が長くなる傾向がみられました。
これが問題の 1 つ目です。
DynamoDB の書き込みコスト
2 つ目の問題が、該当テーブルへの書き込みコストです。
DynamoDB はテーブルやインデックスに割り当てたキャパシティベースでの課金体系となっており、読み込みと書き込みでその金額が異なります。 プロビジョニングされたキャパシティの場合に、同じキャパシティでは、書き込みは読み込みの約 5 倍のコスト(料金)が掛かります。*4
データ自体は小さいものの、計算のために非常に多くの書き込みが発生するため、DynamoDB のコストが大きくかかってしまうことも、中長期的に解決したい問題となりました。
これらの問題に対して、システムパフォーマンス検証時点で問題として上がったものの、リリースのタイミングでは許容できるリスク内容であったため、そのままリリースへ進めました。
しかし、データ量が増えるにつれて段々とリスクが大きくなってくるものでもあったため、改善が必要なことも見えており、計算用テーブルに関する課題として管理することにしました。
改善とその効果
きっかけとなったのは、とあるメンバーのチャットで、「計算対象のチャットルームが少ない場合は制限件数分オンメモリで保持できないか」というもので、
アプリケーション内部でストリーム的にメッセージが流れてくるのであれば、それを常に ID でソートして制限件数分保持することで、計算用テーブル自体を不要にできるのでは?というアイデアです。
計算用テーブルがある場合、特定のチャットルームの処理中にエラーが発生した場合でも、そのチャットルームのみのリトライで処理を再開できるといった運用上のメリットがありました。しかし実際に運用してみたところ、エラーの発生率は極端に低かったこともあり、そのメリットを失っても得られるものが大きいと考えました。
さっそく検証することにしました。Scala には SortedSet, SortedMap というソート済みコレクションが提供されています。その実装は TreeSet, TreeMap というもので、赤黒木をつかって実装されています。 これをつかって、ストリームから要素として流れてくるメッセージをまとまった単位で Insert し、その後制限件数を超えていれば超えている分だけ drop することで、メッセージ ID の新しい順に制限件数分を保持するようにしました。
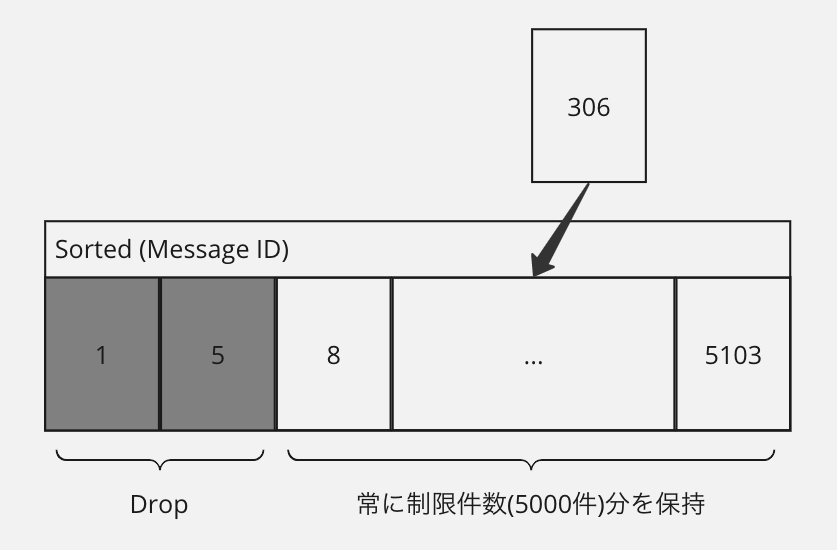
結果、中間テーブルをつかわず、またホットパーティションによってスロットリングリトライが発生していた部分のロスを無くし、コストとパフォーマンスの課題を同時に解決できることが検証できました。
その後の調整(これまたこのアイデアを提案したメンバーからの指摘)で、最終的には SortedMap 等は利用せず、DynamoDB からもソートされて取得できる特性を活用し、さらにパフォーマンスを最適化した実装でリリースすることができました。
これにより、下記を達成し、課題を解決することができました。
- 時間のかかっていた処理を短縮することで、バッチ全体の処理時間を短縮
- 計算用テーブルへの書き込みがなくなったことで、DynamoDB の書き込み費用を削減
まとめ
昨年のフリープランの制限変更における、メッセージ閲覧制限のための情報を計算するアプリケーションについてご紹介しました。
Chatwork では上記のように、各 AWS サービスやデータベースの特性や、アルゴリズムを把握した上でのシステムの改善や最適化、プログラミング言語の表現力を利用した可読性の向上、安全な並行並列処理の実装、それらの運用改善など、エンジニアとして様々なスキルを発揮して、サービスやシステムの課題を解決しています。
他にも様々な課題やその解決事例がありますので、ちょっとでも「聞いてみたい!」と思った方は、ぜひ下記からカジュアルにお話しませんか?