TL;DR
- We used a blue-green deployment strategy for the HBase version upgrade on top of Event Sourcing and CQRS architecture system.
- The deployment approach worked quite well and took only 3 weeks in total to accomplish the project goal. This experience was new and exciting for us. So I want to share it :)
About Database upgrade
A database upgrade is always troublesome and whenever you are dealing with such circumstances in production scenarios you would be super nervous (I would say 100 times compared to other production operations that you are dealing with).
This feeling is hard to share with people who don't have the experience or exposure in operating the Database environments. And I think 99.9% of people would agree if you have the experience and have gone through the hard times in dealing with the database related operations. It is risky and it costs a lot, but upgrade itself doesn't mean that it provides new value to the product and although it's not prioritized in many cases unless there is some urgent reason.
At the same time, it's a huge hidden risk if the database becomes "untouchable" and how to deal with this problem has been a topic across, many developers and operators have been struggling with such situations
Upgrade approach
In general, you would have two choices.
rolling upgrade
One is a rolling upgrade. Upgrading the database version one by one in a sequential manner. I found a good explanation here. Please read this if you're not familiar with the word.
What is meant by a rolling upgrade in software development? - Quora
Pros
- Data is in one place. So you don't need to think about how to sync the data between different clusters and how to guarantee the sync is perfectly working.
Cons
- Once the upgrade is finished, there is no easy way to revert. So if the upgrade triggers performance issue somehow, you would be in big trouble.
- The long-running database has some unexpected state which you can't reproduce on the test environment. Sometimes you need to deal with the problem as it comes to production. And that possibility makes you really nervous.

blue-green deployment
The other is a blue-green deployment. In this case, you have to provision the upgraded database cluster separately and switch the application to use the new one at some point. Please check this blog post if you're not familiar with the word "blue-green deployment".
I think this approach is widespread in web application deployment, but if you replace the word "router" to "application", and "web server" to "database", the same approach can be applied to database upgrade.
Pros
- You don't touch the running production database while upgrading. That makes your life much easy as compared to rolling upgrade approach.
- You can easily revert to old cluster when some unexpected issue happens. And you can also distribute the requests gradually so that you can minimize the scope in case you have some issue (To do this, as in "Cons", you need to sync data from new cluster to old cluster though)
- Because of the factor above, you can somewhat shorten the load testing on the test environment and can proceed with the project speedily.
Cons
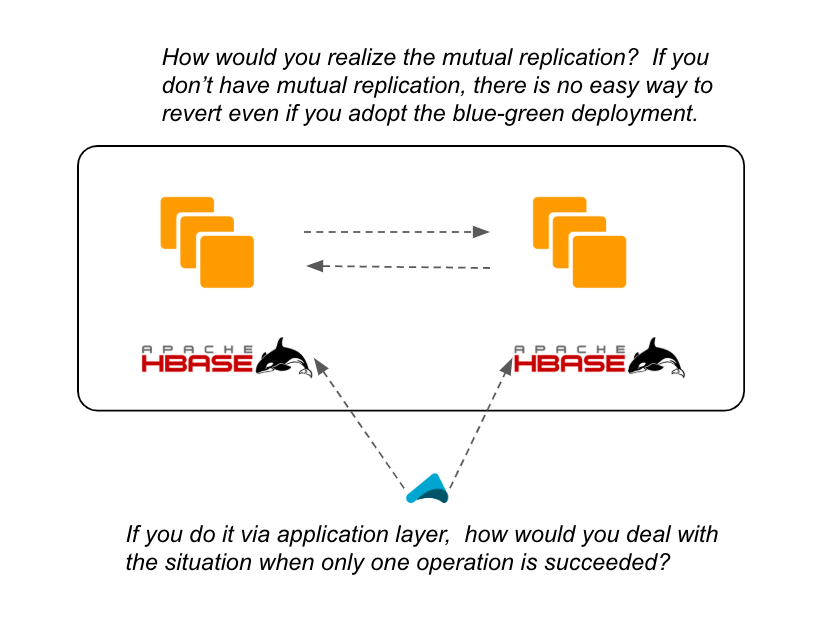
- You need to make sure data is synced between both database clusters. Not only from old cluster to the new cluster, but also from new cluster to old cluster if you want to have an easy way to revert after the upgrade. But mutual data replication is quite difficult in many cases. It can be possible to write to two clusters on every operation, but you need to prepare when only one cluster is down and operation to that cluster only is failed. That handling would be really complicated.
- You need to have double sized servers while running both clusters. That'll cost some money and can be hard if your system is not on cloud infrastructure.
Our approach
Basically, our approach is blue-green deployment. And because we have Kafka in front as event sourcing bus, it was much easier to deal with the data sync problem in "Cons" listed above.
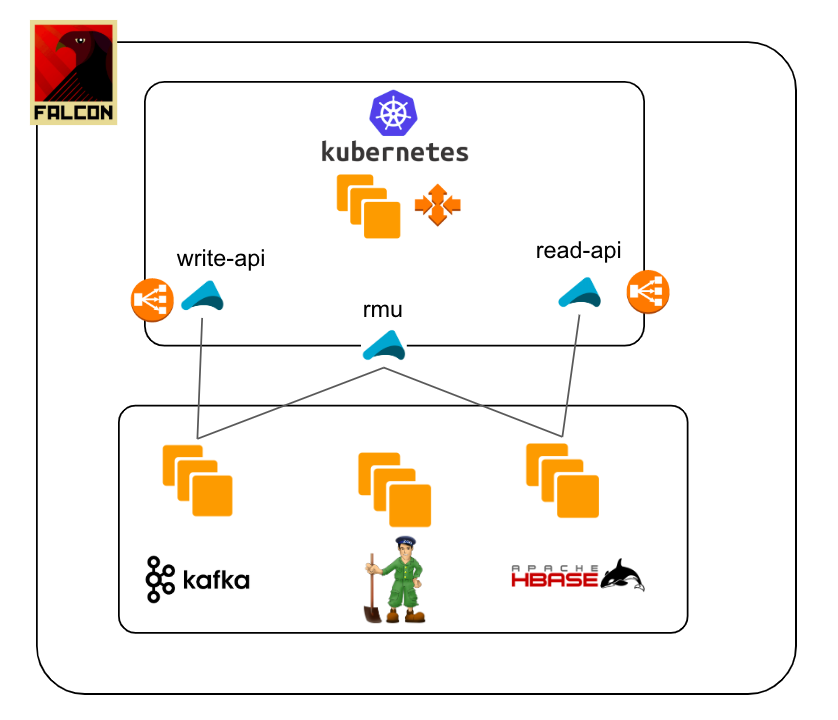
Current architecture
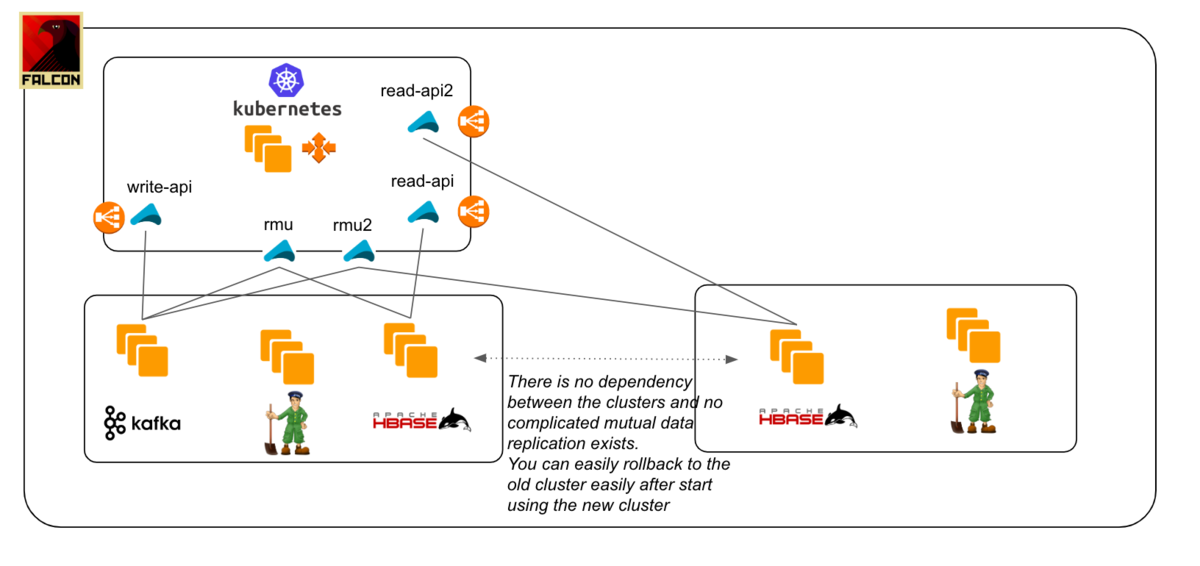
First, let me introduce the basic architecture. Btw, we call the whole chat message sub-system "Falcon". That's why the falcon icon is in the diagram.
- when an end user post a chat message, write-api put message data into Kafka
- read-model-updater ("rmu" in short) fetches data from Kafka, convert it to read-model and put it into HBase
- when an end user read chat messages, read-api pull message data from HBase
I don't explain why we choose CQRS in this post. So, please check the slides below if you want to know in detail or if you are not familiar with the concept of CQRS.
Kafka Summit SF 2017 - Worldwide Scalable and Resilient Messaging Ser…
Worldwide Scalable and Resilient Messaging Services by CQRS and Event…
Database upgrade flow
Now, I'm gonna explain how we did the database upgrade on top of this architecture
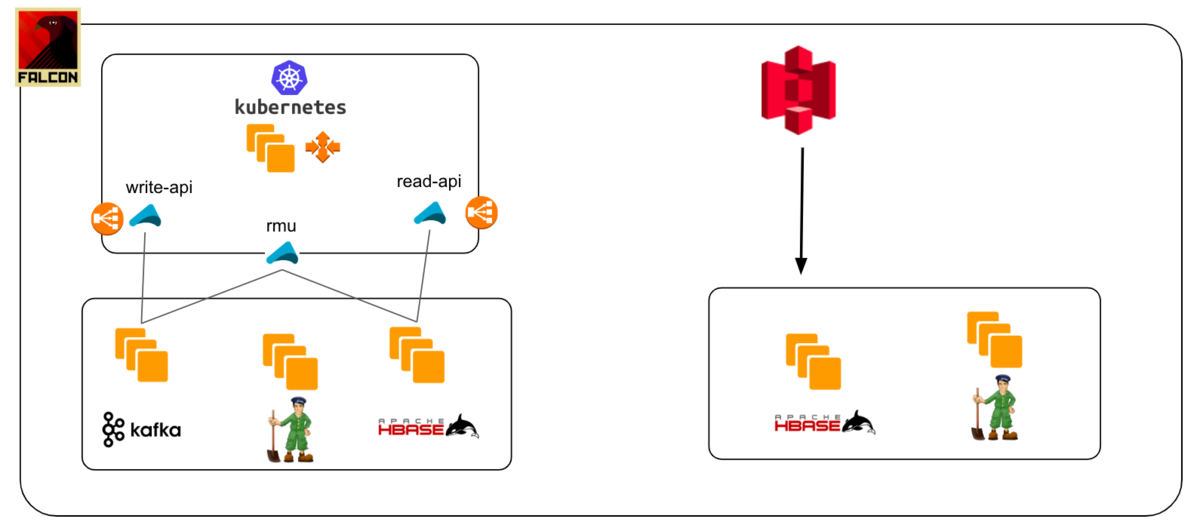
Step1: Prepare new clusters and do initial restore from backup.
Step2: Prepare another consumer(rmu2 in this diagram) to sync data from Kafka to new database cluster. You'll re-play old Kafka events starting from before then the initial restore. Make sure you implement idempotency on your consumer. I mean, the system needs to work properly even if the same event is consumed more than once.
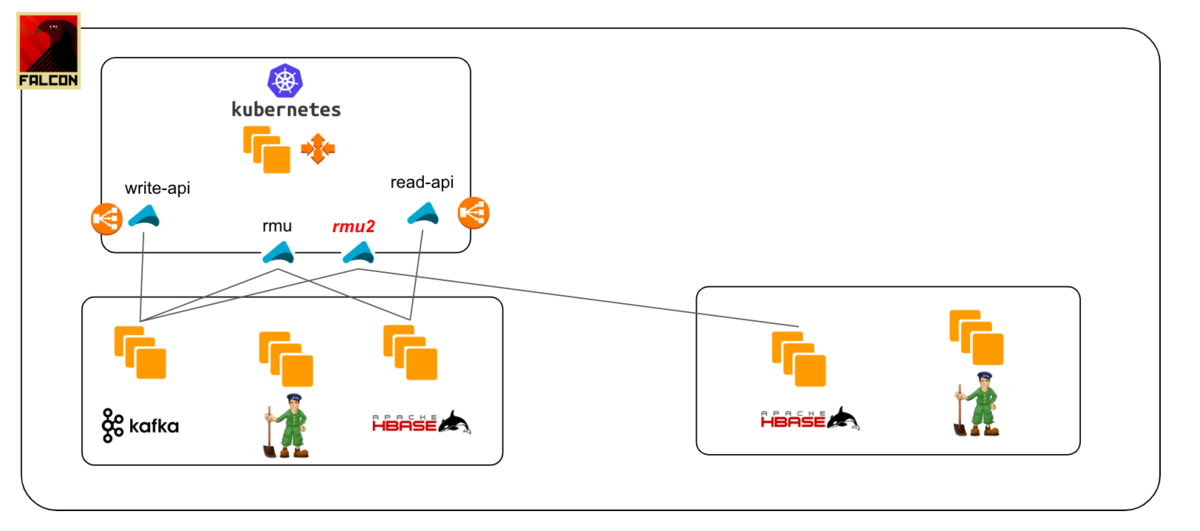
Step3: When the new consumer(rmu2) has caught up with the latest Kafka messages, prepare another read-api pulling data from the new database cluster. And send requests to new read-api gradually.
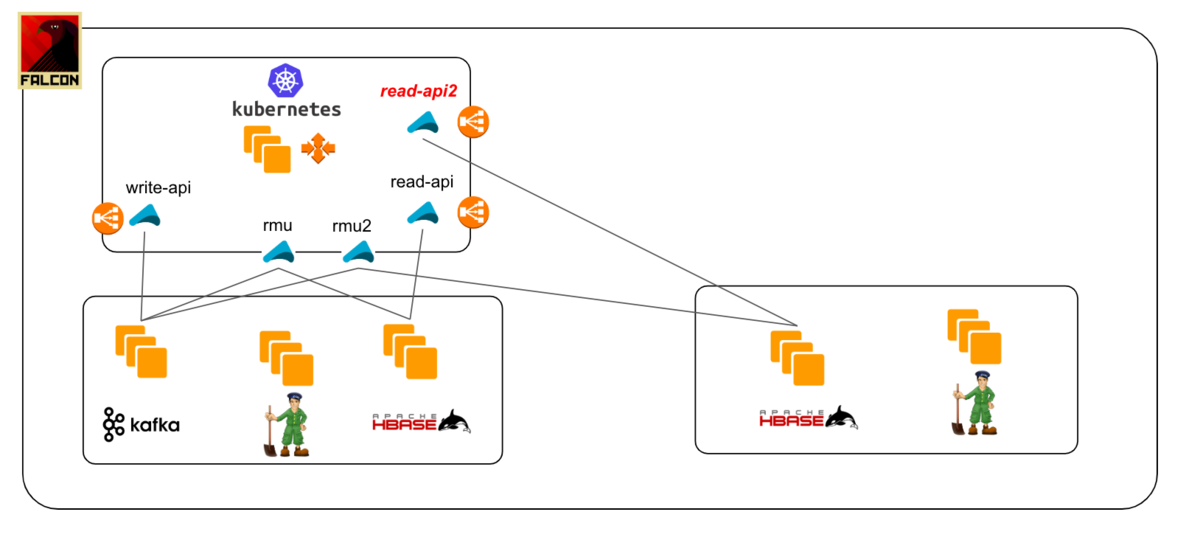
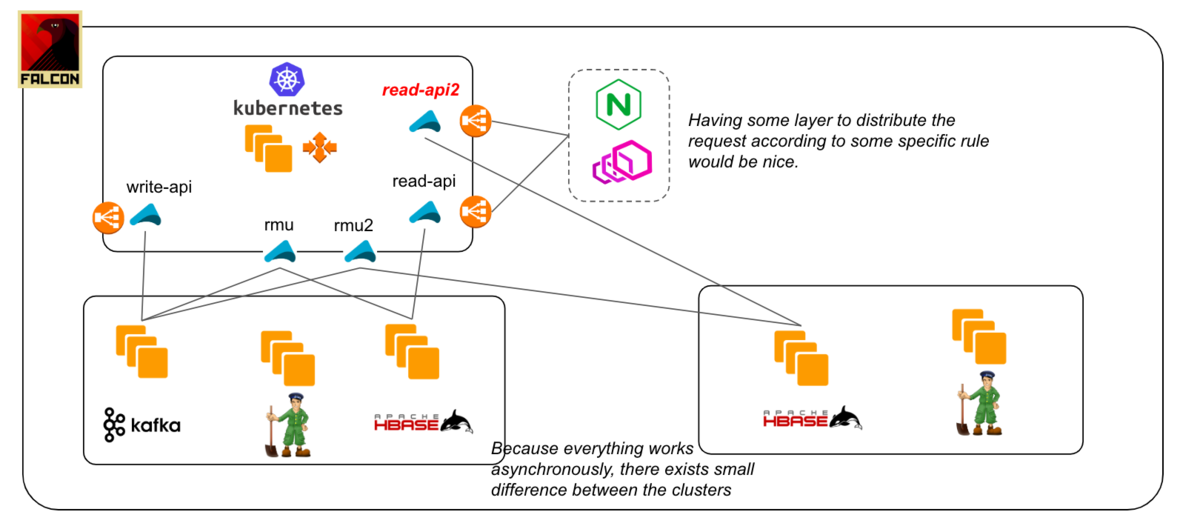
There would be some state difference between the old cluster and new cluster even if data sync is finished in a couple of milliseconds. We had a small issue due to this difference, so you need to confirm and run an assessment check in order to see what kind of issue can be triggered through the difference between clusters and your application logic beforehand. Or if you have some good layers in front of read-api to distribute the request according to user attribute or something (e.g. routing via Nginx or Envoy like proxy), you can just set the proper rule in there and the difference can be handled efficiently and it won't be a problem.
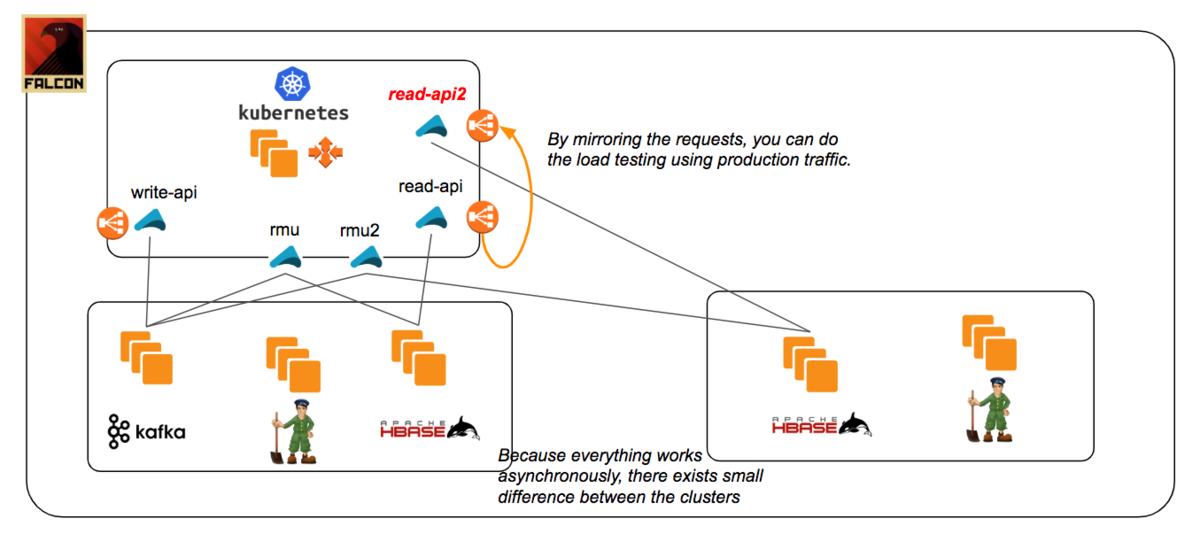
And in the retrospective of this project, we noticed that if you can mirror the requests from existing api to new api, you can do the load testing using production traffic without affecting end-users.
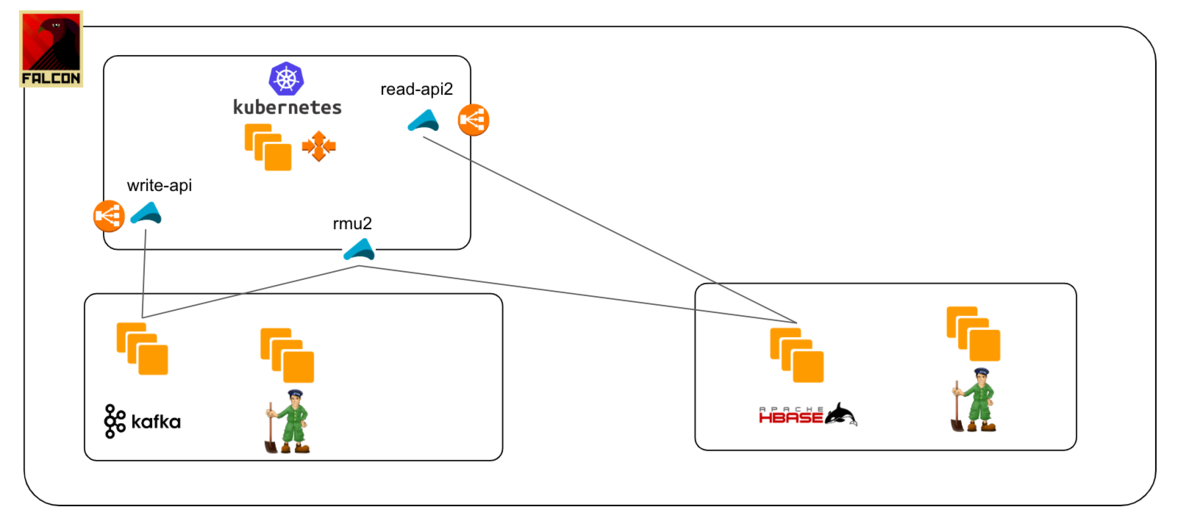
Step4: Switch to new read-api 100% and shut down old clusters and applications when you're sure everything works perfectly.
Why I think this approach is better
Let me explain the difference with the normal blue-green approach. One problem in normal blue-green is that you need to make sure that data is synced on both clusters, ideally not only before the upgrade but also after the upgrade. In this approach, instead of using replication functionality that the database provides, the database updates are applied separately via the application that we write and prepare. This approach brings us a lot of merits.
First, because they are working separately, you don't need to care how data is synced on each phase. Especially, you'll need some extra (and quite tough in most cases) effort in syncing data from new cluster to the old cluster if you want to have an easy way to revert after the upgrade. But in this approach, they're just working independently. So you can just revert to use old ones in case some unexpected issue starts happening after the upgrade.
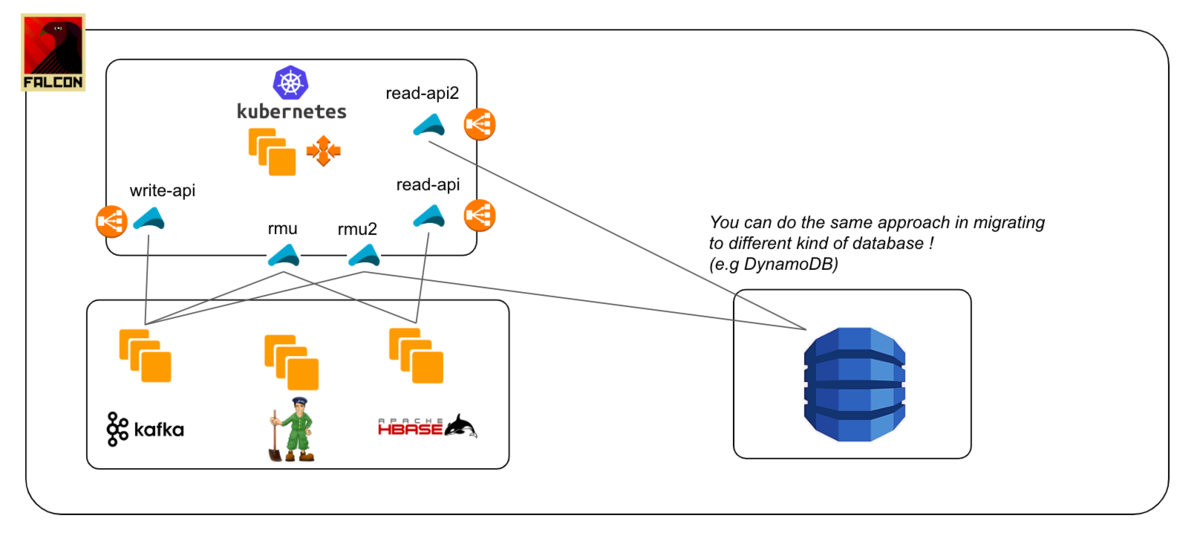
Secondly, you don't need to bother about the version compatibility between old clusters and new clusters. If you use cluster data sync functionality that the database provides, there would be some version restriction and compatibility issue that can occur in some edge cases. But in this approach, all you need to do is to prepare independent application which put data into each database. I think it is the problem you can solve much more easily in most cases. And in theory, not only updating the database version but also you can switch the new cluster to a completely different one (e.g. DyanmoDB) using the same approach. In that case, you can't use the back-up data for initial set-up and need to prepare initial data migration program. That'll take some time, but I think that's the reasonable item to deal with.
Conclusion
CQRS and event sourcing subjects are often discussed in software architecture. From an operational point of view, having one more layer as event bus increases the infrastructure complexity and operation cost. Honestly speaking, I didn't like this approach that much from that view before. But we noticed that it also changes how we operate the infrastructure and bring us the peacefulness in database operation. And yes, I'm a huge fun of CQRS and event sourcing now :)
Next challenge
You might wonder what we would upgrade Kafka(event sourcing bus)? Yeah, that'll be our next challenge. I hope there exists a better approach than normal rolling upgrade and blue-green deployment. Engineer life goes on!
And we're hiring engineers who love middleware upgrade!