こんにちは!SREグループの桝谷@hnchn87です。
先日7月11-12日に開催された『SRE NEXT 2025』にPlatinumスポンサーとしてブース出展してきました。この記事では、当日ブースで実施した「SREエンジニア実態調査」のアンケート結果と、「あなたが体験した"ヒヤリハット"集」の集計結果を大公開します!
当日、アンケートやヒヤリハット事例の投稿にご協力いただいた皆様、本当にありがとうございました!!
アンケートの概要
今回のSRE NEXT 2025では、以下の2つの企画を実施しました:
- SREエンジニア実態調査: SREエンジニアの皆様の技術スタック、組織体制、関心事などを調査
- ヒヤリハット集: SRE現場で経験した「ヒヤリハット」な体験談を収集
どちらも多くの方にご参加いただき、SRE業界の現状を把握できる貴重なデータが集まりました!
1. SREエンジニア実態調査の結果
回答者数: 144名の方からご回答をいただきました。
インフラの構成管理について
インフラの構成管理には、主に何を利用していますか?

やはりTerraformが圧倒的に多く、Infrastructure as Codeの定番ツールとしての地位を確立していることがわかります。次に従来からある構成管理ツールのAnsible、Chef、Puppetが続き、最近注目されているAWS CDKも4分の1程度の方が利用されていました。
利用しているパブリッククラウド
主に利用しているパブリッククラウドは何ですか?
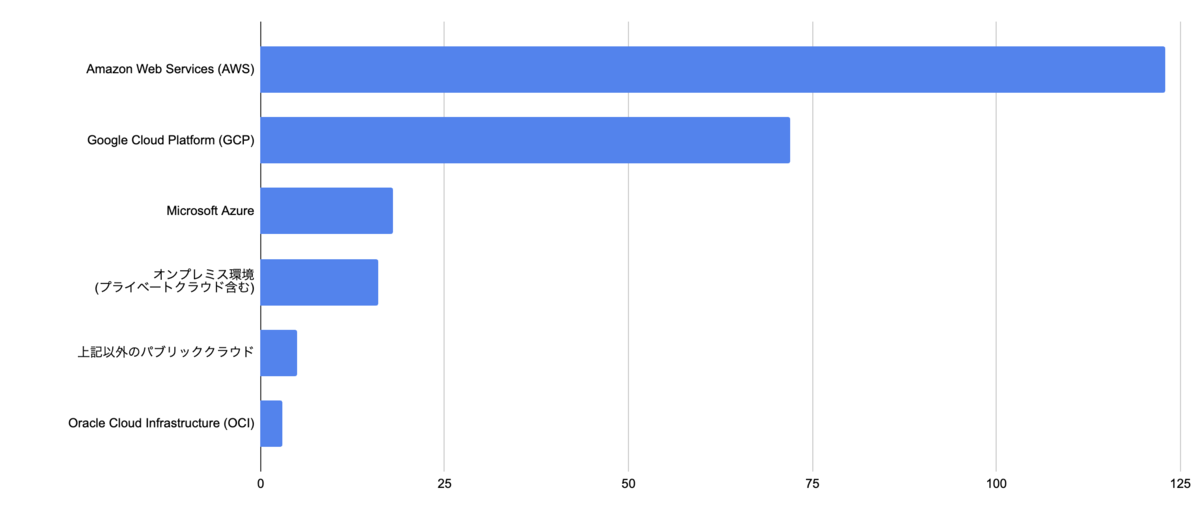
AWSが圧倒的なシェアを占めており、GCPが続いています。マルチクラウドを採用している組織も多く、複数のクラウドプロバイダーを使い分けている実態が見えました。
アプリケーションの実行環境
アプリケーションの主な実行環境は何ですか?

コンテナとサーバーレスの採用が進んでいることがわかります。Kubernetesも多くの組織で活用されており、モダンなアプリケーション実行環境への移行が進んでいる様子が伺えます。
SREの組織体制
あなたの組織のSREは、どのような形態に最も近いですか?

Embedded SRE(開発チーム内にSREが所属)とPlatform SRE(共通プラットフォームを提供)がほぼ同数で、組織の規模や文化に応じて最適な形態を選択している様子が見えます。
SLI/SLOの導入状況
SLI/SLOの導入・活用はどの程度進んでいますか?

SLI/SLOについては、多くの組織で試行錯誤している段階であることがわかります。完全に組織的に導入できている組織はまだ少なく、今後の課題として認識されていることが伺えます。
可観測性ツール
可観測性 (Observability) の実現のために、どのツールを主に利用していますか?

Datadogが最も多く利用されており、統合的な可観測性プラットフォームとしての人気の高さが伺えます。クラウドプロバイダー独自のツールや、OSSのGrafana + Prometheusの組み合わせも多く活用されています。
CI/CDパイプライン
CI/CDパイプラインには、主に何を利用していますか?

GitHub Actionsが圧倒的に多く、GitHubを中心とした開発フローの普及を反映しています。GitOpsツールのArgo CDも25件と、モダンなデプロイメント手法への関心の高さが見えます。
関心を持っている技術・コンセプト
SREの領域において、あなたが現在最も関心を持っている技術やコンセプトは何ですか?

Platform Engineeringが最も多く、SREの次のステップとして注目されています。また、AI/LLMの活用も多くの関心を集めており、SRE業務の自動化・効率化への期待が高まっています。
2. あなたが体験した"ヒヤリハット"集の結果
総票数: 183票
SRE現場で経験した「ヒヤリハット」な体験談を募集したところ、多くの貴重な事例が集まりました。

BEST5のヒヤリハット
- もう使用されていないと思ったシステムを止めたら実は使われていた: 23票
- デプロイ先をテストと本番で間違えそうになった: 13票
- 本番サーバーを止めた: 9票
- 開発環境と間違えて本番環境のDBを削除: 7票
- DBの作業で数時間ロック: 7票
カテゴリ別 全ヒヤリハット事例
収集したヒヤリハット事例を、カテゴリ別に分類してすべてご紹介します。 ※Claudeさんに分類してもらったので分類がおかしくてもご容赦ください。。。
環境・デプロイ間違い(13件、32票)
- デプロイ先をテストと本番で間違えそうになった
- リリースするつもりのない機能がリリースされてしまった
- PRのマージ先を間違えて本番にデプロイ
- 間違ってテスト時に本番環境をメンテナンスモードにした
- prodをstgと間違えて変更しそうになった
- stgのDBにprodのデータを流した
- stgで負荷試験をしたらprodのオートスケーリングが壊れた
- フレームワークチームとの調整ミスにより本番リリース後にモバイル全台停止
- stgではうまくいっていたのにprodにあげた直後にバグ発見
- 本番リリースでリソース展開忘れてた
- prod環境を更新したらリクエストが多くサーバーが死亡
- 間違えて本番データでテスト
- 認証基盤リプレイス時にユーザー情報を異なる環境にマイグレーションした(devからstgだったのでヒヤリで済んだ)
データ関連の操作ミス(20件、40票)
- 開発環境と間違えて本番環境のDBを削除
- DBの作業で数時間ロック
- TerraformをApplyすると本番DBが再作成された
- データ更新が止まっていたことに3ヶ月後に気付いた
- prodのDBを削除
- お客さんのDBを消した
- データパッチを当てたらデータが壊れた
- テーブル削除のつもりがDB削除
- 開発環境を削除
- マネジメントコンソールから本番のDynamoDBデータ全削除
- ローカル環境のDBのテーブルを削除したつもりがQA環境のDBのテーブルを削除
- GCPの本番PJを削除
- バックアップファイルを誤って削除
- クラウドのアカウントを削除したらまだリソースが残っていた
- ユーザーのどこまで本を読んだかのデータを1/8吹っ飛ばして消えた
- S3のオブジェクトを消す時に残っていたペースト情報から削除してしまった
- 1年目の時にDBのバックアップを削除して怒られた
- RDSのデータをexportしたらdisk fullに
- SQLを間違えてストレージを使い切った
- SQLの指定するIDがずれていた
システム・インフラ停止(11件、31票)
- もう使用されていないと思ったシステムを止めたら実は使われていた
- 本番サーバーを止めた
- 本番サーバーのパッケージを開発サーバーと間違えてデリートしてしまった
- 作業手順を間違えて一部サーバーを停止
- 間違い電話でDR環境のサーバーが誤って起動した
- 4時間サービスを停止した
- サービスメッシュの設定を間違ってサービス停止
- 勝手にglibcのバージョンを上げてシステムがぶっ壊れた
- 空白一文字でクラスター全断
- サイトが落ちた
- k8sの必要なリソースを削除してしまいPodがほぼいなくなった
設定・構成ミス(12件、19票)
- ルーターの設定を間違ってみんなリモートワークできなくなった(夕方だったのでセーフ?)
- CIを実行したらTerraformの設定が意図しない値に更新された
- サービスのタイムアウト設定を間違ってサーバーを高負荷状態にした
- AWS SCPの設定ミスで障害発生
- AWS SESのアクセスキーの入れ替えをミスりそうになった
- コアルーターのCPUがはりついた
- GCPのFire Wall設定がフルオープンに
- IAP設定し忘れてstg環境が全世界に公開
- 操作対象のKubernetesのコンテキスト設定を間違えていた
- Fastlyの設定をミスって全断
- CDNの設定ミスで通常リクエストがブロックされた
- DBサーバーの通信を全てブロックする設定にした
監視・運用プロセス(15件、22票)
- オンコール受けて「対応します」と言って寝落ちして数時間・・・
- SRE NEXTの荷物の発送を忘れそうになった
- 早朝メンテの時間に寝坊しかけた
- サービスが止まる変更にシャワー中に気づいた
- インフラメンテでサービスが止まりかけた
- バッチが動いていなかった
- 先輩の作成したサービス切替手順を使用したら当日データエラーになった
- 許可を得てないのにサーバーにログインして不明なアクセス事件になった
- アラートに気付くのが遅れたユーザーに影響が出た
- オンコール起きれなかった
- オンコール対応で起きたら家からログインできなかった
- DBストレージアラートを設定し忘れていた
- 脆弱性対応でOpenSSHが削除されサーバへSSH出来なくなった
- 本番負荷試験で負荷がかけられていなかった
- バックアップの検証中にネットワークをパンクさせた
コスト・リソース管理(7件、15票)
- クラウドサービスの費用体系で見落としが
- 負荷試験のインフラを起動したままにのがコスト増加
- あるツールでAWSの連携をしたらトラフィックが増えコスト増(翌日に気付いた)
- 一時ファイルを大量生成してinodeを使い切った
- インスタンスタイプ間違えて過負荷
- HPAがあるのにreplicasを定義して削除してしまいPodが1個になった
- CI実行したら増強したはずの台数が元の台数に戻った
人的ミス・うっかり(12件、21票)
- OSSライブラリにパッチを当てたら思わぬバグが!
- dryrunだと思ったら違った
- CIを壊してリリースを3日間止めた
- 重複配信をして同一ユーザーに30件配信
- Renovateを動かして他のブランチを全て消してしまった
- リダイレクトのURLを間違えて2日間利用出来ないユーザーが出てしまった
- indexを貼り忘れた
- GitHubのリポジトリに全くの別人を招待
- テストをしっかりするようになって事前にバグをたくさん発見できるようになった
- 検証環境の中で rm -rf /
- ライブラリをよくわからず使っていたら必要な実装が漏れていた
- オフィスの停電で社内NASが立ち上がらなくなった
おわりに
ヒヤリハット事例について実際に現地でお話し聞くのとても楽しかったです! 今後もこうしたカンファレンスへの参加を通じて、SREコミュニティの発展とエンジニア同士の知見共有に貢献していきたいと考えています。
最後に、今回のアンケート調査とヒヤリハット事例の投稿にご協力いただいた皆様、改めてありがとうございました!
お知らせ
今回の『SRE NEXT 2025』のアフターイベントとしてスポンサー8社による合同LT&交流イベントを開催します!
こちらではSREグループの山下@task2021がAtlantisについてお話しする予定ですのでぜひご参加ください。
私も現地には行く予定です。
timeedev.connpass.com