この記事は Chatwork Product Day 2023 応援記事です!
はじめまして。プロダクト開発部の @daido1976 です。
先日「Chatwork」の iOS アプリで名刺読み取り機能をリリースしたので、その機能と実装方法について紹介させていただきます。
名刺読み取り機能とは
モバイルのカメラアプリで名刺を読み取って、記載されているメールアドレスや電話番号から「Chatwork」への招待やコンタクト申請を送れるようにする機能です。*1
以降は名刺読み取り機能の実装方法について紹介していきます。
名刺画像を解析する処理の流れ
名刺読み取りのコア部分である、名刺画像を解析する処理の流れを図にすると以下のようになります。

まず、名刺画像を解析して記載されている内容を文字列として出力します。この部分はいわゆる OCR(光学文字認識) という技術を用いて行われます。
次に出力された文字列の中から名前や電話番号、メールアドレスなどを抽出します。この部分は自然言語処理の一つである 固有表現抽出 と呼ばれる情報抽出の技術が使われます。
自分の理解では前述の通り、名刺(その他の例だと請求書、レシート、身分証明書など)の読み取りは OCR で文字を認識した上で自然言語処理などを用いて情報を抽出する、という流れになるのですが、最近ではそれらをひっくるめて AI-OCR、または単に OCR と呼んだりしている例もあるようです。
この記事でも情報抽出を含む技術のことを単に OCR と呼ぶことがあります。
OCR サービスの比較・検討
今回はなるべく素早く機能リリースを行いたかったため、OCR には外部のサービスを利用することにしました。 選択肢の中の一部を抜粋して、検討結果を記載します。
AWS
Amazon Textract と Amazon Rekognition という OCR サービスがありましたが、どちらも日本語非対応だったので今回の選択肢からは外しました。
Amazon Textract can extract printed text, forms and tables in English, German, French, Spanish, Italian and Portuguese.
Detecting text - Amazon Rekognition
Amazon Rekognition is designed to detect words in English, Arabic, Russian, German, French, Italian, Portuguese and Spanish.
GCP
文字認識を行うための Cloud Vision API と自然言語処理を行う Natural Language API の二つを組み合わせることで実現できると考えましたが、実際には Natural Language API が名刺読み取りには使えない精度だった(本来文章解析用である様子)ので、選択肢から外しました。
自分の使い方が悪いのかと何度も試しましたが、ドキュメントを読むとそもそも Entity の Type に EMAIL がなく、メールアドレスが OTHER として認識されるので、今回は利用できませんでした。
Entity | Cloud Natural Language API | Google Cloud
Azure
Azure AI Document Intelligence *2は文字認識に加えて、名刺を解析する用のモデルがあるので、このサービスのみで名刺読み取りが実現できます。
動作を検証してみた結果、精度や速度も問題なかったので、Azure AI Document Intelligence を採用することに決めました。
以降は実装時点での最新バージョンであった REST API v3.0(2022-08-31)版 での情報をもとに記載します。
全体のアーキテクチャ
名刺読み取り全体のアーキテクチャは以下の図の通りです。
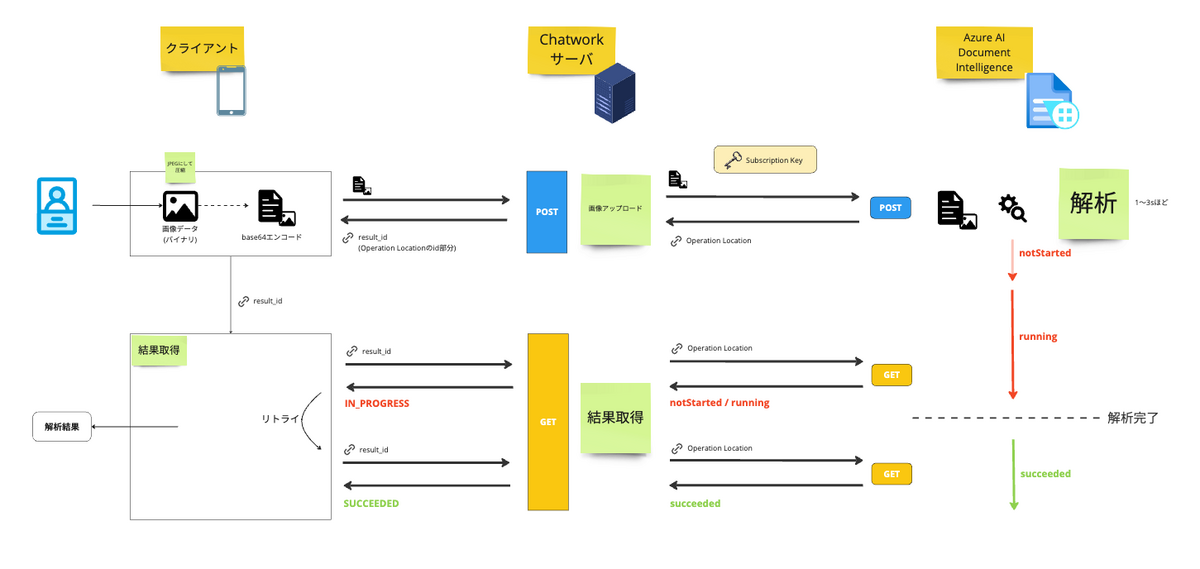
以下にアーキテクチャの補足や実装時のポイントを列挙します。
- 名刺画像を解析する処理は Document Intelligence に委任し、サーバでは基本的に入力値の検証やレスポンスの整形などを行うのみ
- 解析結果取得には 1〜3 秒程度かかるので、サーバ側は Document Intelligence と同じく 非同期な API として設計し、クライアント側でポーリングさせる
- 元々サーバ側でポーリングさせようかと考えていたが、レスポンスに最大 3 秒かかるような API は、マルチスレッドで捌くとはいえスケーラブルな設計になっていないのでやめた
- ポーリングの間隔は 公式ドキュメントの推奨 に従い、1 秒間隔としている
- クライアント側で画像データの圧縮をする(ファイルフォーマットは PNG と比べて圧縮率の良い JPEG 固定)
- 開発環境では Document Intelligence の Free プランを利用しているが、Free だと画像データの入力は最大で 4MB まで
- モバイルデータ通信環境下で 4MB 程度のデータを送信すると、クライアントからデータ送信する部分がボトルネックとなり全体の処理に 10 秒ほどかかってしまったので、パフォーマンスを改善するために 1MB 以下まで圧縮するようにした
- 名刺画像を Base64 エンコードして送るか、バイナリのまま multipart/form-data で送るかは、取り回しの良い Base64 エンコードを選択
- Base64 エンコードすることで、バイナリに比べるとファイルサイズが約1.33倍になるのは許容した
- Document Intelligence 側では Base64、バイナリどちらにも対応している
- Document Intelligence では 勤務先電話番号と携帯電話番号が判別できる ので、携帯電話番号のみ表示するようにしている
最後に
今回は先日リリースした名刺読み取り機能について紹介しました!「Chatwork」の iOS 版アプリをご利用中の方はぜひ触ってみてください!
それではまた^^
*1:記事公開時点では iOS 版アプリのみの対応です