こんにちは。データエンジニアのみっつと申します。
CTO室というところで次世代データ分析基盤プロジェクトというものを推進しております。 2022/09/01で入社(中途)してから1年が経ち2年目に突入しました。前職では長年アドテクノロジー分野の大規模データ処理を経験し、Chatworkへはデータエンジニア(DRE)第1号として入社しました。 最先端プロジェクトを任せていただけたからかか、1年が過ぎるのはアッという間でした😅(歳を重ねたからもありそう...)
さて、10/07(金)Chatworkが主催するオンラインカンファレンス『Chatwork Product Day 2022』が実施されます。それに合わせ、弊社社員がほぼ毎日ブログを投稿していきます! lp.chatwork.com
今回はその取り組みの一環で、入社以来取り組んで来たChatworkの次世代データ分析基盤について紹介します!
そもそもデータ分析基盤とは?
プロダクトサービスを確実に提供することが目的のデータベース(OLTP)に対して、主に分析が目的(OLAP)のデータを処理するのがデータ分析基盤です。
OLTPがリアルタイムに数多くのデータを不整合なく処理できることが最重要、に対してOLAPは大量データを効率的に処理できることが最重要です。 具体的によく使われるモノは、OLTPではRDB(MySQL, PostgreSQL, Oracle)、OLAPではBigQuery, Redshift, TreasureData, Snowflake…etcが挙げられます。
Webサービスを提供する場合、OLTPが必須なのに対して、OLAPの方は無いとサービス提供出来ない類のモノではないため、OLAPはピンと来ないという方も少なくないかもしれません。
しかし、その歴史は古くインモンやキンボールらによる分析モデルが1990年代初頭に提唱されました。そこから、データウェアハウス、データマート、ディメンショナルモデル、スタースキーマ、DataValut2.0…etcのようなキーワードに代表されるような仕組みが生まれ、データ分析基盤と呼ばれるデータ分析システムを構成するようになります。
近年、WebサービスもSaaSに代表されるように継続して利用されるサービスへ進化することが当たり前となり、データ分析の重要度は益々高まっていきています。
もはやChatworkのようなプロダクトにとっては生命線となったと言っても過言ではないかもしれません。
数年先のデータ利活用を見据えた、次世代データ分析基盤
Chatworkは下記の中長期経営計画を掲げ、長期的にはビジネス版スーパーアプリを目指しています。

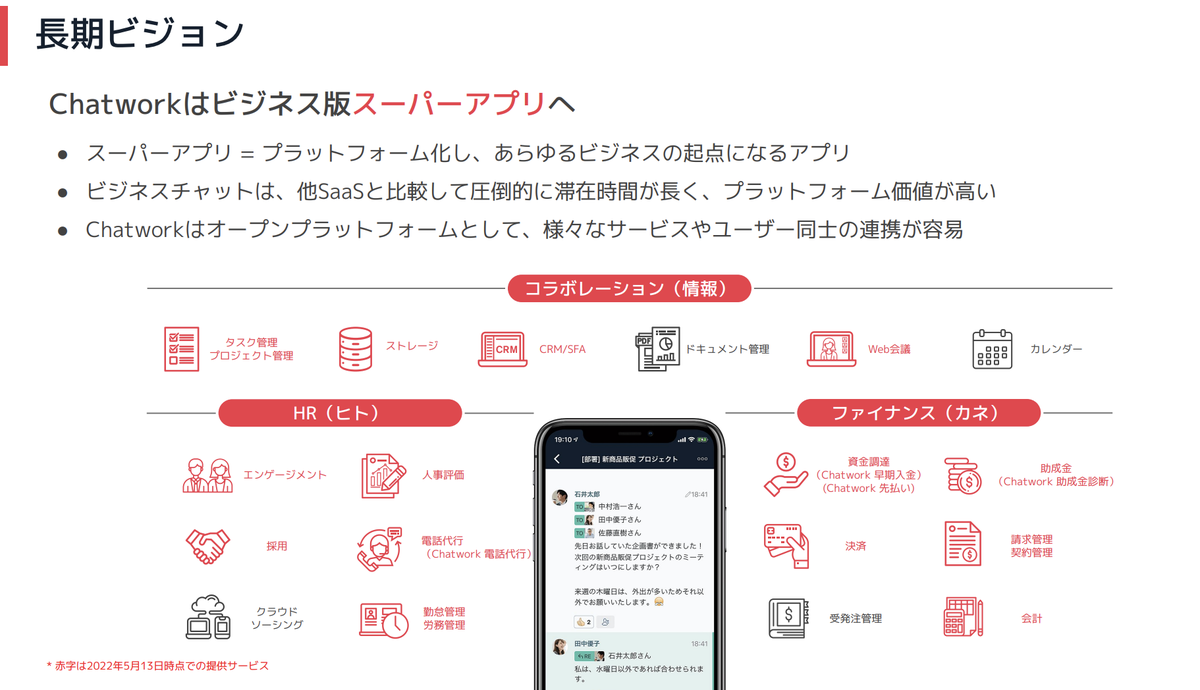
この計画を推進するデータ戦略にフィットするDWHとしてSnowflakeを選定し、次世代データ分析基盤として実装を進めています。
Snowflakeの評価ポイント3点
Snowflakeを次世代データ基盤として選定したポイントを3点に絞って紹介します。
1. ストレージとコンピュートの分離
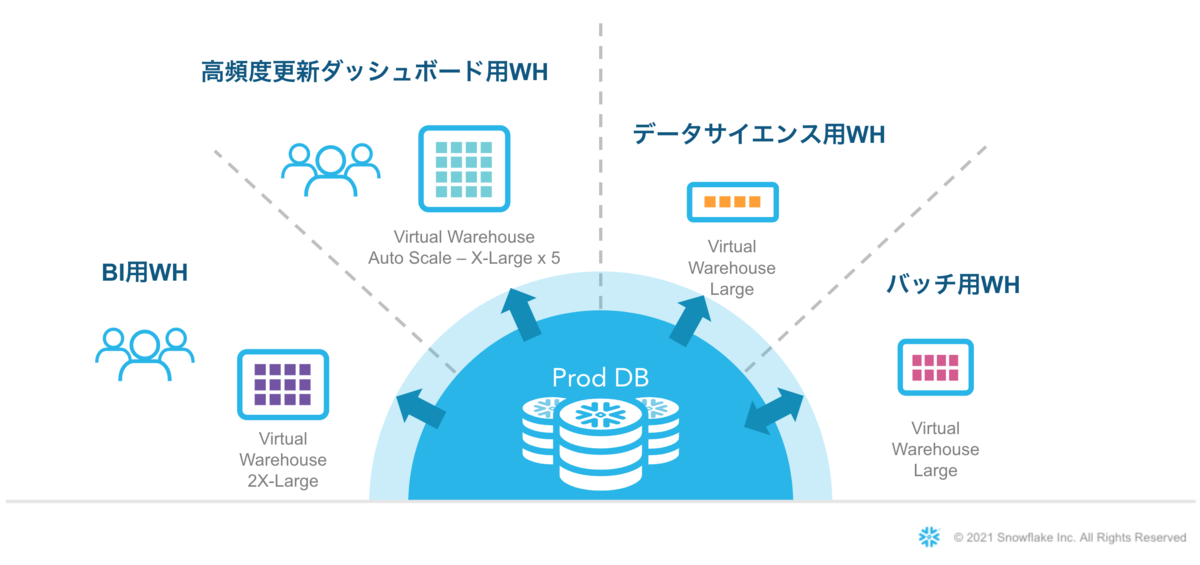
データを保持するストレージと、クエリを実行するコンピュート(仮想ウェアハウス)が完全に分離したアーキテクチャとなっています。 これにより、特定のDBにロードしたデータに対して、並列に幾つでもコンピュートリソースを立ち上げることが可能となり、並行して動いても互いに一切影響を受けません。
図のように、役割別にコンピュートリソースを設定する運用にすると、 「どこかの部署が重いクエリを動かしているからクエリが重い」「裏でバッチ処理が動いているからクエリが重い」ようなことは起こりません。
スーパーアプリ化によりデータ連携が多くなると、中央であるChatworkのデータは関係各所色々な部門で参照されることが多くなると想定されます。
そんな見通しに対して、このアーキテクチャにより、コンピュートリソースの配分は、割り当てる仮想ウェアハウスを分けるだけの運用で可能となり、どんなに周辺サービスが成長しようとも無限に拡張可能となる安心感があります。
2. 開発・運用労力を省力化するのに便利な機能が揃っている。
- ELT(Extract → Load → Transfer:データをまず取り込んでから加工する)を実現する強力なサポート機能群
- クラウドストレージ(S3)へ書き出し可能なデータであれば、自前の開発・運用不要でデータを取り込めます。
- 外部ステージと半構造データクエリ
- クラウドストレージ(S3, GCP)にあるデータに対して直接クエリを実行できる仕組みです。この機能により取り込む前のデータも素早く確認可能です。取り込みプロセスでしばしば起こるストレスフルなロード問題をスキップできます。
- Snowpipe
- クラウドストレージの指定したパスを監視し、ファイルがputされたらニアリアルタイムで自動ロードする仕組みも自前の開発・運用不要で利用可能となります。
- エコシステムを経由したデータ接続で省力化
- クラウドストレージ(S3)へ書き出しや、直接接続が実現していないSaaS系データ(Salesforce, Market, Zendesk…etc)のデータの取り込みもパートナーエコシステム(Fivetran,hightouch...etc)を経由することで、自前で開発・管理することなく可能となります
- その他、dbtを使ったデータモデル構築やTerraformを使った環境構築も可能で、CI/CDやIaCのようなDevOps技術で開発効率を追求するデータ分析基盤の仕組みも構築できます。
3. データクラウドにおけるデータ共有機能に期待できる。
- 「データは一箇所、利用はあらゆる場所で」を実現する仕組み。
- データ共有は即座に開始でき、即座に利用可能で停止も可能、遅延なく提供側と利用側で同じデータを参照可能です。
- データ利活用を自社に閉じない利用へ昇華する取り組みも可能へ
- 強力で柔軟なセキュリティ保護をかけた上で、複数企業間でのデータ連携を高品質、低コストで直ちに実施できる仕組みがあります。
- 「1. ストレージとコンピュートの分離」と合わせてデータは共有元の所有物、クエリ実行は利用側のリソースを使うという分離が成り立ち、アーキテクチャの観点からも自社に閉じないデータ利活用が促進されます。
- Snowflakeネイティブデータアプリケーション(プレビュー)
- パッケージアプリケーションの形で、データだけでなく可視化も含めた配布可能となりより安全で手軽なデータ共有を促進することを期待できます。
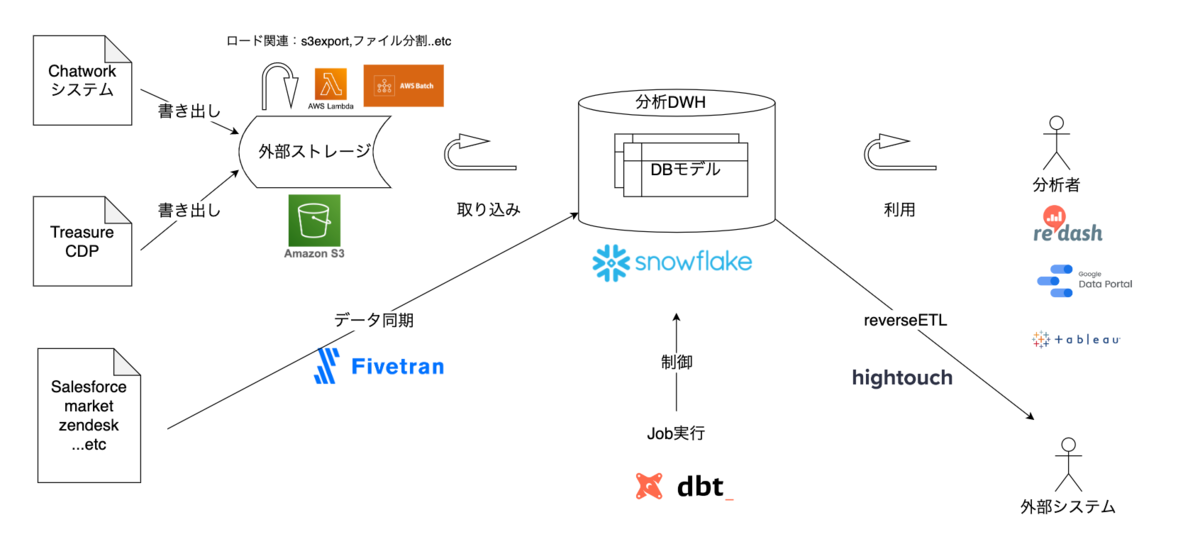
Snowflakeを中心としたデータ分析基盤の技術スタック
技術スタックは下記のような構成で構築しています。
データフロー概要図
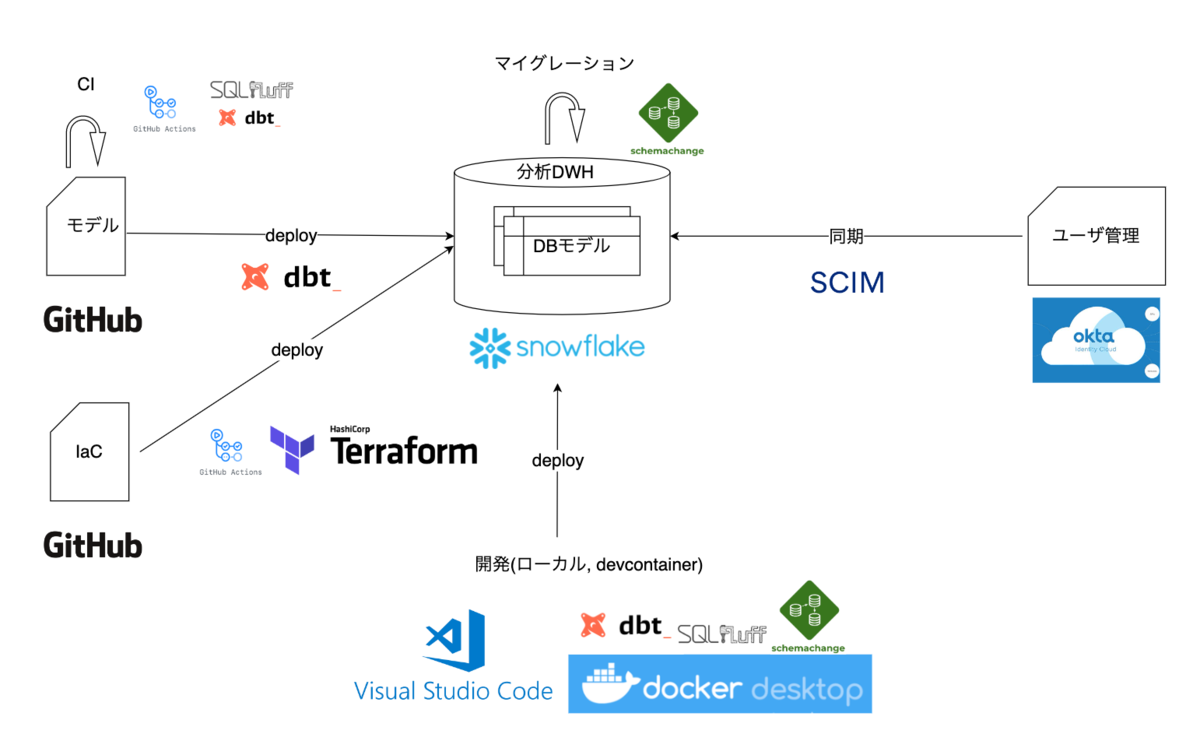
DevOps概要図
(説明は長くなってしまうため割愛します。詳しく知りたい、ここはどういうこと?...etc ありましたらコメント欄、もしくは面談にて話しましょう)
生産性〜働き方もバージョンアップ
DevOpsの概要図でお気づきになった方がいるかも...なところですが、開発はローカル環境で立ち上がるコンテナにて行います。 これはチームメンバーから、開発環境を構築する手間や各種ツールのバージョン不整合を起こしたくないとの意見が上がって実現しました。
実際CI/CDやIaCに加えて、リポジトリからクローンするだけですぐに始められる開発環境は生産性向上に大きく寄与しています。 現状のチーム体制は、フルタイムが自分一人+業務委託メンバー3人で、リモート勤務・非同期コミニュケーション下での開発が基本ですが、順調に進んでいます。
まだまだ
とはいえ、次世代データ分析基盤開発は数年かけて完成させていく予定で、始まったばかりです(2022/06/29に社内向けα版ローンチ〜)
足りてない部分、実現したい機能がまだまだたくさんあります!
さらに開発を加速するため、次世代データ分析基盤構築エンジニア採用はじめました。 このような取り組みに興味持っていただける方、ご応募お待ちしております! hrmos.co